深度学习补充二
关于深度学习用于文本和序列
- 深度学习算法分别是循环神经网络与一维卷积神经网络
应用场景
- 文档分类和时间序列分类, 比如识别文章的主题或书的作者
- 时间序列对比,比如估测两个文档或者两支股票的相关程度
- 序列到序列的学习,比如将英语翻译成法语
- 情感分析,比如将推文或电影评论的情感划分为正面或者负面
- 时间序列的预测,比如根据某地最近的天气数据来预测未来的天气
核心术语
- 文本向量化是指将文本转换为数据张量的过程
- 讲文本分解而成的单元叫做标记,将文本分解成标记的过程叫做分词.所有文本向量化的过程都是应用某种分词方案,然后将数值向量与生成的标记相关联.
- 向量与标记做关联一般有:对标记做one-hot编码;与标记嵌入,通常用于单词,叫做词嵌入。
注意:轻量级浅层文本处理模型时,可以使用logistic和随机森林.使用n-gram是一种功能强大,不可或缺的工具
利用keras实现单词级的one-hot编码
1 | from keras.preprocessing.text import Tokenizer |

1 | one_hot_results = tokenizer.texts_to_matrix(samples,mode='binary') # 获得ont-hot二进制表示 |

1 | word_index = tokenizer.word_index |
注意:使用one-hot最有可能出现的是散列冲突。可能两个不同的单词具有相同的散列值
利用keras实现词嵌入
- 词嵌入有两种方式:一种是在完成主任务的同时学习词嵌入,一开始是随机的词向量.然后逐步通过学习加深
- 在不同于待解决的问题的机器学习任务上预计算好词嵌入,然后加载到模型中.这些词嵌入叫作预训练词嵌入
1 | from keras.datasets import imdb |

注意:在嵌入序列上添加循环层或一维卷积层,将每个序列作为整体来学习特征
使用预训练的词嵌入
下载原始文本
1 | import os |

对原始数据进行分词
1 | from keras.preprocessing.text import Tokenizer |

1 | # 打乱顺序 |
使用词嵌入进行处理
1 | # 解析词嵌入和构建词嵌举证 |

1 | embedding_dim = 100 |
构建模型
1 | from keras.models import Sequential |
1 | model.layers[0].set_weights([embedding_matrix]) |
训练模型与评估
1 | model.compile(optimizer='rmsprop', |

1 | import matplotlib.pyplot as plt |
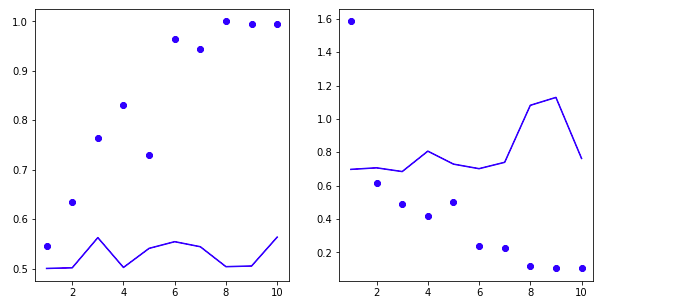
不使用预训练词嵌对比
1 | model = Sequential() |
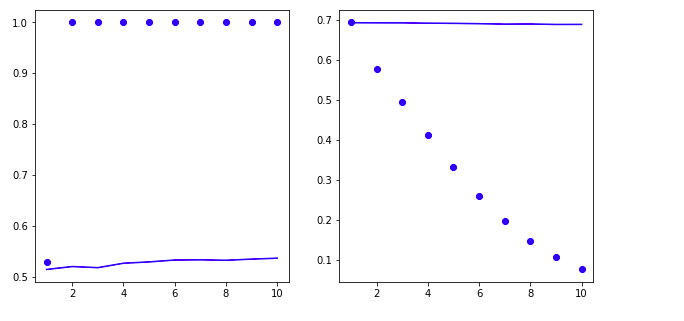
泛化到测试集中
1 | imdb_dir= '/Users/Yun/Desktop/wangweijie/aclImdb' |

循环神经网络
simpleRNN不擅长处理长序列的文本.一般使用LSTM或者GRU层
LSTM直译的说就是带长记忆的短期记忆,多了一条时间轨道
1 | from keras.datasets import imdb |
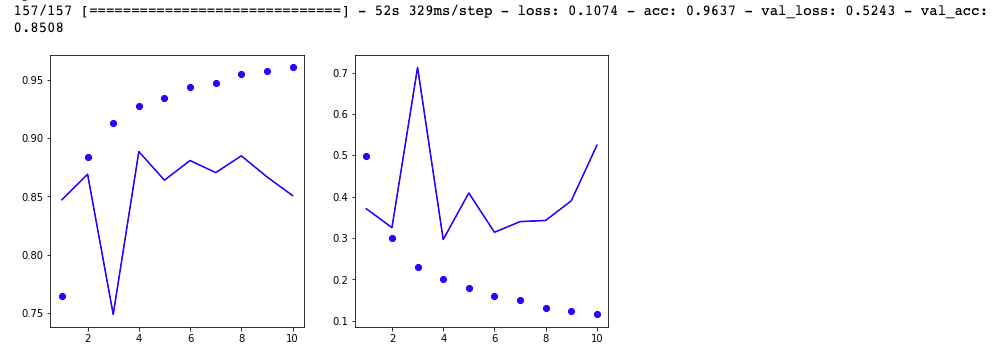
高级用法
- 循环dropout
- 堆叠循环层
- 双向循环层
观察数据
1 | import pandas as pd |

1 | import os |

1 | import numpy as np |
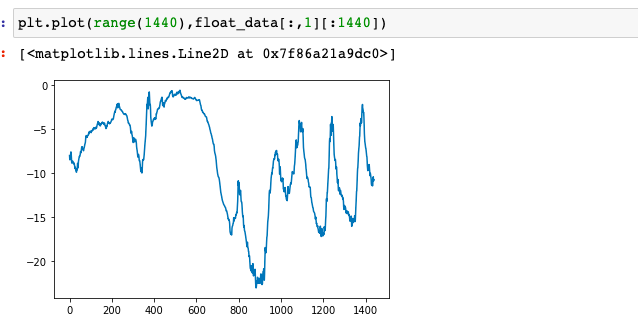
1 | plt.plot(range(1440),float_data[:,1][:1440]) # 时间是否和温度有关联 |
数据标准化
1 | mean = float_data[:200000].mean(axis=0) |
通过生成器产生数据
1 | ''' |
1 | lookback = 1440 |
基于常识非基准的方法
1 | def evaluate_naive_method(): |

基本的机器学习
1 | from keras.models import Sequential |
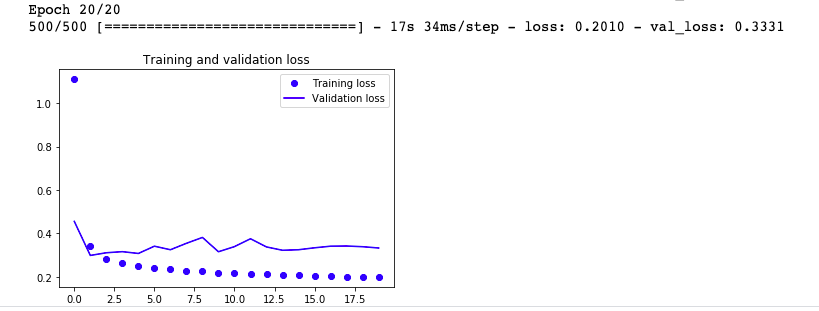
循环网络+DROUPT
1 | from keras.models import Sequential |
1 | from keras.models import Sequential |
循环层堆叠
增加网络容量通常是增加每层单元数或者层数
1 | from keras.models import Sequential |
使用双向RNN
1 | def reverse_order_generator(data, lookback, delay, min_index, max_index, |
1 | model = Sequential() |
双向RNN细节
1 | model = Sequential() |
1 | from keras.models import Sequential |
利用一维卷积处理
1 | from keras.datasets import imdb |
一维
1 | from keras.models import Sequential |
一维和RNN
1 | model = Sequential() |
总结
- 使用RNN可以进行时间序列的回归.分类等
- 一维卷积神经网络可以用于机器翻译
- 序列数据的整体顺序很重要可以使用循环来处理
- 如果不重要可以使用一维卷积处理,比如句首发现关键词和句尾发现关键词很有意义