机器学习平凡之路十
- 无监督学习聚类与降维
- 半监督和自监督以及生成学习概念
聚类
聚类就是让机器把数据集中的样本按照特征的性质进行分组
K均值算法
- 先确定K的数值
- 从一大堆数据中随机挑选K个数据点,作为质心
- 不断遍历每一个数据点,计算它们与每一个质心的距离
- 重复以上步骤,找到新的质心,直至收敛
K值的选取
手肘法基于对聚类效果的一个度量指标来实现的。K值很小的时候,整体损失很大,随着K值的增大,损失函数会逐渐出现一个拐点。此时K值就是比较好的值
聚类:为客户分组
1 | import numpy as np |
X = dataset.iloc[:,[3,4]].values # 针对两个特性进行聚类
1 | from sklearn.cluster import KMeans |
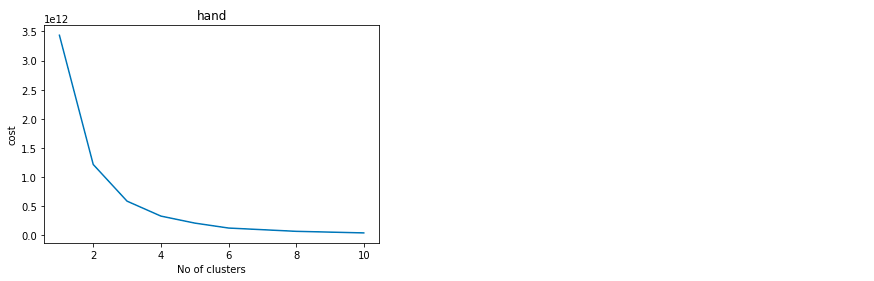
可以看出在3和4,聚类的个数是最优的
1 | # 把聚类可视化 |
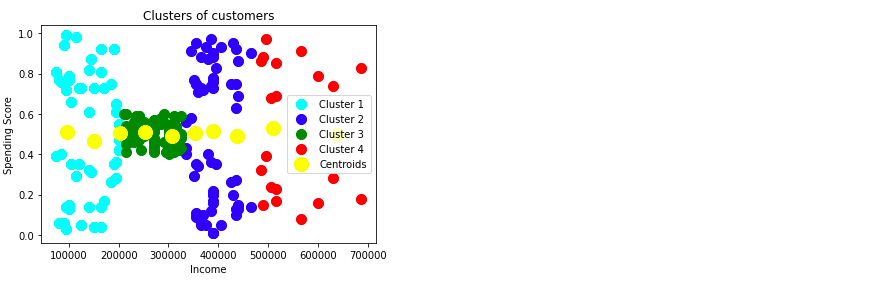
PCA算法
最常见的降维算法是主成分分析、通过正交变换将可能相关的原始变量转换为一组各维度线性无关的变量值。用于提取数据的主要特征分量,以达到压缩数据或提高数据可视化程度的目的
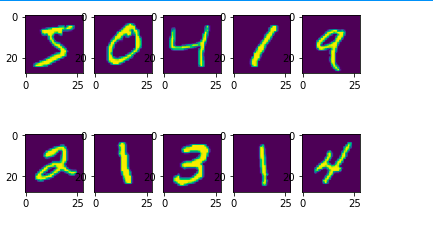
对手写数字集进行降维
1 | from keras.datasets import mnist |
1 | for each in range(10): |
1 | from sklearn.decomposition import PCA |
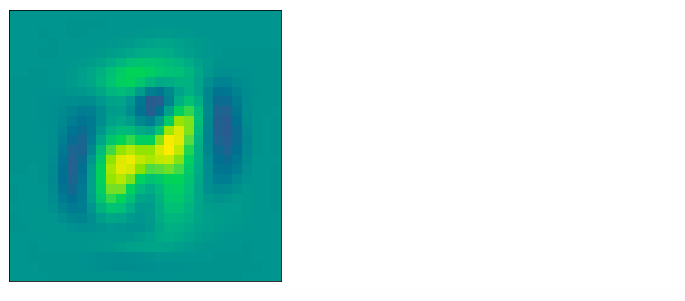
可以看出来识别数字主要在中间的这几块
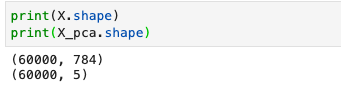
特征从784个转变到5个特征
GAN的实现
1 |
|

这个是训练了5400次所生成的图片。距离以假乱真还有一些距离
思路
1、随机选取batch_size个真实的图片。
2、随机生成batch_size个N维向量,传入到Generator中生成batch_size个虚假图片。
3、真实图片的label为1,虚假图片的label为0,将真实图片和虚假图片当作训练集传入到Discriminator中进行训练,训练的loss使用均方差。
4、将虚假图片的Discriminator预测结果与1的对比作为loss对Generator进行训练(与1对比的意思是,如果Discriminator将虚假图片判断为1,说明这个生成的图片很“真实”),这个loss同样使用均方差