机器学习平凡之路九
- 集成学习
- 随机森林,梯度替身决策树,XGBoost算法
- 偏差和方差
集成学习
集成学习就是机器学习里面的协同作战。也相当于几个不大一样的模型组合起来,很可能效率会好过一个单独的模型
偏差和方差
偏差和方差是机器学习性能优化的风向标
方差定义是一组数据距离其均值的离散程度。机器学习的偏差用于衡量模型的准确程度
偏差的评判是机器学习模型的准确度。偏差越小,模型越准确。度量了算法预测与真实结果的离散程度。刻画了学习算法本身的拟合能力。好比每次打靶,比较靠近靶心
方差评判的是机器学习模型的稳定性,方差越小,模型越稳定。度量了训练集变动所导致的学习性能变化,刻画了数据扰动所造成的影响。每次打靶,不管打的准不准,击中点比较集中。
噪声,噪声表达的是在当前任务上任何学习算法所能达到的泛化误差的下界。刻画了学习问题本身的难度。属于不可约减的误差
降低偏差与方差
- 给定一个学习任务。模型对训练集的拟合不够完善,会出现高偏差
- 当充分训练后,训练好的模型应用于测试机,并不一定有好的效果。模型应用于不用的数据集,会出现高方差。也就是过拟合的状态
- 机器学习性能优化领域的最核心问题。就是寻找偏差和方差之间的最佳平衡点。训练集优化和测试集泛化的平衡点
- 性能优化是有顺序的,一般是先降低偏差,在聚焦于降低方差。
- 同样的数据集大小对偏差和方差的有一定的影响
Bagging算法-多个基模型的聚合
算法的基本思路是从原始数据集中抽取数据,形成K个随机的新训练集。然后训练处K个不同的模型。
过程如下:
- 每轮抽取n个训练样本(有些样本可能被多次抽取,有些样本可能一次都没有被抽取。叫做有放回的抽取,这个过程也叫做自助采样)
- 每次使用一个训练集得到一个模型,K个训练集得到K个模型。模型称作为基模型,基模型有两种情况:
- 分类问题,K个模型采用投票的方式得到分类结果
- 回归问题,计算K个模型的均值作为最后的结果.
树具有显著的低偏差,高方差的特点。Bagging算法,就从树模型开始,解决太过于精准,不易泛化的问题。
在Bagging中,有两种模型BaggingClassifier和BaggingRegressor用于分类问题和回归问题
代码示例
1 | import numpy as np |
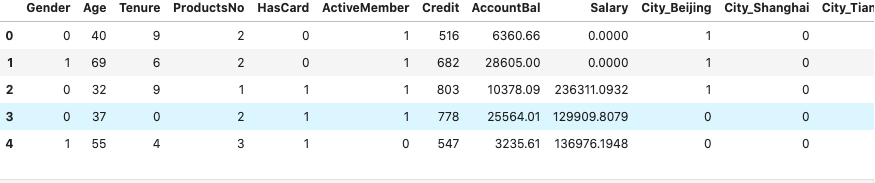
1 | # 拆分数据集为测试集和训练集 |
1 | # 对多棵决策树进行聚合 |

使用网格优化参数
1 | from sklearn.model_selection import GridSearchCV |

从树的聚合到随机森林
假设树分叉时选择的特征数m
- 对于分类问题,m可以设置为特征数的平方根
- 对于回归问题,m可以设置为特征数的1/3
RandomForestClassifier 和 RandomForestRegressor分别适用于分类问题和回归问题
1 | from sklearn.ensemble import RandomForestClassifier |

使用极端森林
极端森林不去考领所有的分支,而是随机选择一些分支,从中拿到一个最优解
1 | from sklearn.ensemble import ExtraTreesClassifier |
需要注意的点:
- 随机森林在大多数情况下优于极端森林
- 极端森林不考虑所有的分支,速度比较快
- 某些数据,极端森林拥有更强化的泛化能力。
Boosting算法
- 每一轮的中有针对性的改变训练数据
- 集成弱模型,不断的进行选择优化
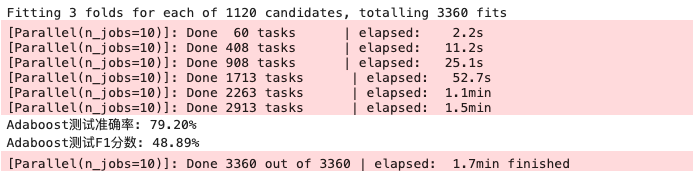
AdaBoost算法
给不同的样本分配不同的权重,分错的样本权重在过程中增大。新模型会更加关注这些被分错的样本,然后将修改过权重的新数据集输入下层模型进行训练。最后将每次得到基模型组合起来。
1 | from sklearn.ensemble import AdaBoostClassifier # 导入AdaBoost模型 |
梯度提升
1 | from sklearn.ensemble import GradientBoostingClassifier # 导入梯度提升分类器 |

XGBoost算法
一般叫做极端梯度提升
1 | from xgboost import XGBClassifier # 导入XGB分类器 |

对于很多浅层回归和分类。Boosting算法都是生成一棵树后根据反馈,生成另一颗树
Bagging是降低方差,利用基模型的独立性.Boosting是降低偏差,基于同一个模型
Voting算法
1 | from sklearn.ensemble import VotingClassifier # 导入Voting分类器 |

Stacking算法
步骤1 定义stacking方法
1 | # stacking |
步骤2 导入基模型
1 | from sklearn.tree import DecisionTreeClassifier # 导入决策树模型 |
步骤3 使用全新的数据集,以及不必与基模型有关联
1 | # Stacking的实现-用逻辑回归模型预测新特征集 |
