机器学习平凡之路七
- 循环神经网络
- 实例操作
循环神经网络
序列数据
序列数据,是特征的先后顺序对于数据的解释和处理十分重要的数据
语音数据,文本数据都是序列数据。比如一句话放在前面或者放在后面,会使文意有很大的不同
文本数据集的形状为3D张量(样本,序号,字编码)
时间序列数据,按时间顺序进行收集,用于描述现象随时间变化的情况,如果不记录时间戳,数字本身就没有意义
序列数据可以应用的场景:
- 文档分类,识别新闻的主题和书的类型,作者等
- 文档或时间序列对比,比如估测两个文档或两支股票的相关程度
- 文字情感分析,比如评论等情感划分为正面或者负面
- 时间序列预测,预测某地天气的历史数据来预测未来天气。
- 序列到序列的学习,比如两种语言之间的翻译
使用循环神经网络专门处理序列数据而生。它是一种具有记忆功能的神经网络,特点是能够把刚刚处理过的信息放进神经网络内存中。
原始文本如何转化为向量数据
通过One-hot编码分词
1 | from keras.preprocessing.text import Tokenizer |

会存在一个问题本来2个单词,增加到了30维度。一般也就是常人说的维度灾难。解决这个问题,就是使用词嵌入。降低其维度,让本来的0,1本成包含一个意义的数字
实例操作
用Tokennizer进行分词
1 | import pandas as pd |
1 | from keras.preprocessing.text import Tokenizer |
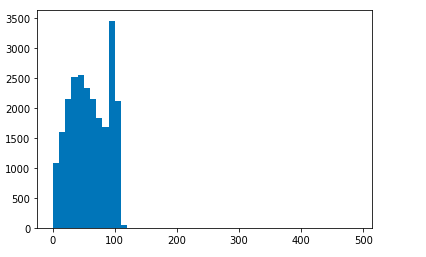
大部分的评论长度都在120以内
1 | from keras.preprocessing.sequence import pad_sequences |
通过pad_sequences截取成相同的长度,长度大于120截断,小于120,填充无意义的0值
构建SimpleRNN
1 | import tensorflow as tf |

1 | history = rnn.fit(X_train,y_train, |

1 | y = rnn.predict(X_test[1]) |
预测结果代码使用
定义恒星是否有行星环绕
代码如下
1 | from sklearn.utils import shuffle # 导入乱序工具 |
以上是CNN和RNN的组合
函数式API构建
1 | from keras.optimizers import Adam # 导入Adam优化器 |
构建多头网络
1 | # 构建正向网络 |
需要注意的点
- 数据集在升维之前,数据集进行逆序
1 | X_train_rev = [X[::-1] for X in X_train] # 数据逆序之后再进行升阶 |
- 训练模型时同时指定正序和逆序数据集作为输入
1 | model.fit([X_train, X_train_rev],y_train, |