机器学习平凡之路四
- 分类
- 逻辑回归
分类
事物的类别比如,根据客户的收入,存款,性别等为客户的信用等级分类
读入图片,为图片内容分类
分类的过程就是确定某一事物隶属于某一个类别的可能性大小的过程
通过Sigmoid函数 g(z) = 1/1+e的-z次方
逻辑回归做的事情就是把线性回归输出的任意值,通过数学上的转换,输出0-1的结果
逻辑回归解决二元分类的问题
数据的准备与分析
1 | import numpy as np |
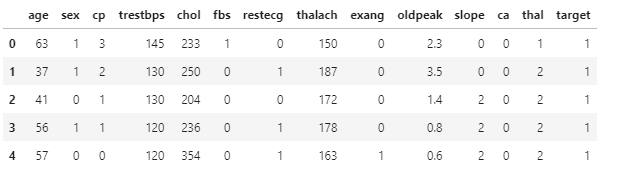
1 | df_heart.target.value_counts() # 查看心脏病的分类数统计 |

1 | # 显示年龄与最大心率两个特性与是否患病之间的关系 |
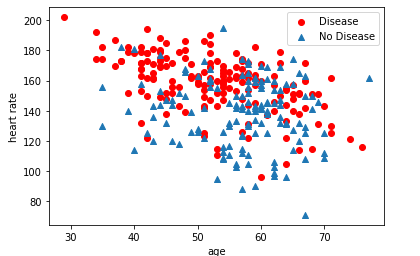
构建特征和标签集,数据特征缩放
1 | X = df_heart.drop(['target'], axis = 1) # 构建特征集 |

1 | from sklearn.model_selection import train_test_split |
建立逻辑回归模型
逻辑函数的定义
1 | def sigmoid(z): |
使用线性回归模型
1 | from sklearn.linear_model import LogisticRegression |

关于哑特征
注意观察cp和thal和slope。它们的取值都在0-4,但是计算会认为这个可以比较的数值。所以要做一定的处理
1 | a = pd.get_dummies(df_heart['cp'], prefix ='cp') |

多元分类
多元分类本质就是训练好多个二元分类器之后,做预测的时候将所有二元分类器都运行一遍。对每一个输入样本,选择最高可能性的输出概率
多元分类的损失函数
多元分类的标签有以下两种格式
- 一种是通过one-hot格式编码分类
- 一种是直接转换为类别数字
- 如果通过one-hot 则应该使用分类交叉熵
- 如果通过标签编码,则应该使用稀疏分类交叉熵
正则化和欠拟合,过拟合
标准化,规范化,归一化,是调整数据
正则化是调整模型,和约束权重
过拟合现象是机器学习无法回避的。降低拟合一般增加数据集的个数,找到模型优化试的平衡点,添加正则化
正则的本质是崇尚简单化,以最小化损失和复杂度为目标
- L1正则化,根据权重的绝对值综合来惩罚权重,有助于不相关或者几乎不相关的特征的权重正好为0,从而将这些特征从模型中移除
- L2正则化,根据权重的平方和惩罚权重,线性模型中,能够增强泛化的目的
- L1是套索回归,L2是岭回归
实际案例
数据准备和分析
1 | import numpy as np |
分割数据集
1 | from sklearn.model_selection import train_test_split |
使用逻辑回归
1 | from sklearn.linear_model import LogisticRegression |

自动调整参数
1 | import warnings |
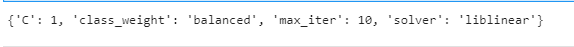
1 | classifier = LogisticRegression(**clf.best_params_) |
