机器学习平凡之路三
- 线性回归
网店销售额预测
步骤说明
明确定义所解决的问题——网店销售额的预测
数据收集和预处理环节分5步走
- 收集数据
- 收集的数据可视化,熟悉数据的结构
- 做特征工程,使数据更好的被机器识别
- 查分数据集为训练集和测试集
- 做特征缩放,把数据压缩到比较小的区间中
选择合适的机器学习算法
- 确定机器学习的算法(线性回归算法)
- 确定线性回归的假设函数
- 确定线性回归的损失函数
通过梯度下降训练机器,确定内部参数的过程
进行超参数调试和性能优化
简明的说就是发现一个能有此到彼的函数,如果函数只包括一个自变量和一个因变量,这个就是一元线性回归。包含2个以上的自变量就是多元线性回归
步骤一数据读取和可视化
1 | import numpy as np |
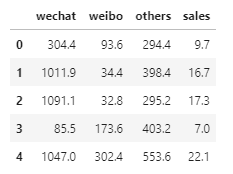
步骤二数据的相关分析
1 | import matplotlib.pyplot as plt |
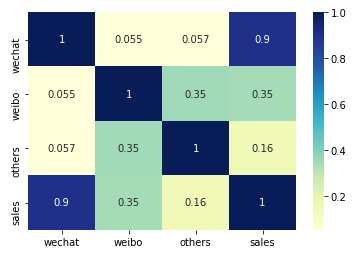
通过相关系分析,可以得知销售额和通过微信投入的是最有效地正比
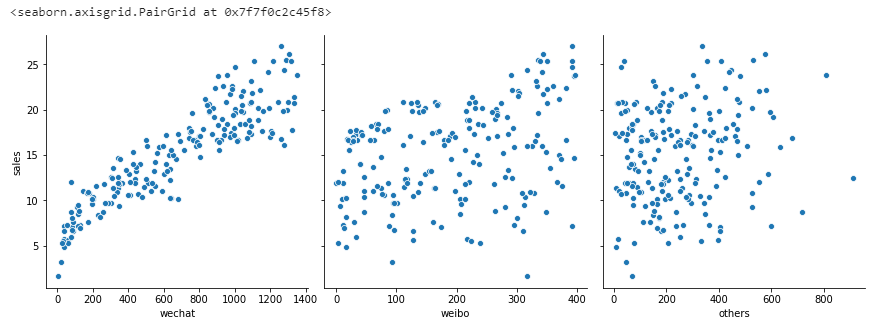
1 | sns.pairplot(df_ads, |
步骤三数据集清洗和规范化
上面的图可以发现微信广告的投入和销售额的相关性比较高,所以就只保留微信投入和销售金额
1 | X = np.array(df_ads.wechat) # 构建特征集。 |
对于回归问题的数值类型数据集,机器学习模型读入的规范格式应该是2D张量.形状为(样本数,标签数)
步骤三拆分变形后的数据集
1 | X = X.reshape(len(x),1) |
步骤四数据归一化
归一化,相当于数据的分布不变,但是值都落入一个小的特定区间。
常见的一个归一化公式如下 x = x-min(x) / max(x)-min(x)
1 | '''from sklearn import preprocessing |
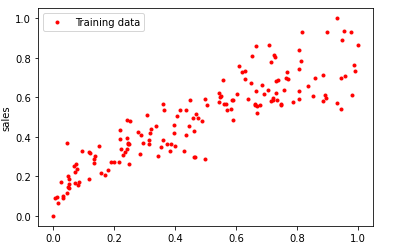
步骤五选择合适的机器学习模型
- 确定选用什么类型的模型
- 确定模型的具体参数
说明
y = ax+b (a代表直线的斜率,b是截距也就是与y轴相交的位置)
y = wx+b (w替换成a代表权重,参数b称作为偏置)
假设函数
y-hat = wx+b
h(x) = wx+b (h(x)就是假设函数,也可以叫做预测函数)
机器学习的目标就是确定假设函数h(x)同时也是在确定w和b
损失函数
比如一个模型3x+5和100x+1,哪一个更好,损失是对糟糕预测的惩罚。损失也是误差,也称作成本或代价,也就是当前预测值和真实值之间的差距体现。因为每一组不同的参数,机器会针对样本数据集算一次平均损失,计算平均损失是每一个机器学习的必要环节
损失函数的表现形式为L(w,b)
损失函数一般有 L2损失函数,L1损失函数,平均偏差误差函数 (回归)
交叉熵损失函数,多类SVM损失函数(分类)
均方误差函数的实现过程:
- 对于每一个样本y-yhat,这是预测值和真实值的差异,但损失值与参数w和b有关
- 将损失值进行平方,平方后都变为正数,这个值叫做单个样本的平方损失
- 所有平方损失相加,根据数量求平均值。
1 | # 定义损失函数 |
通过梯度下降找到最佳参数
训练机器,成为拟合的过程。为了确定内部的w和b。怎么才知道他们的最佳值了。最无脑的方式就是,随其生成1万个w和b的不同组合。然后挨个计算。确定一万种最优的。不过最好的理想结果是每做一次都更接近真相。也就是最精髓的梯度下降
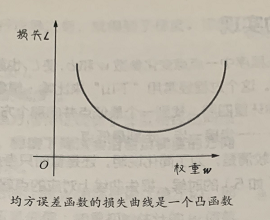
通过凸函数确保有最小损失点。比如L和W单独看。
w和b共同作用
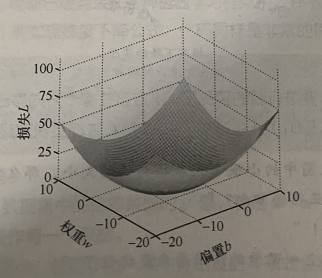
关于梯度下降的实现
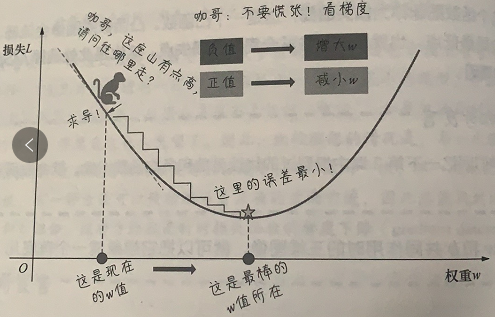
通过导数,描述函数在某点附近的变化率。求导后为梯度为正值。说明L随着W的增大而增大,反之减小
梯度具有两个特征也就是方向和大小,通过梯度下降法会沿着负梯度方向走一步,以降低损失

关于学习速率
求导知道了后,接下来是学习速率,也就alpha
梯度下降实现
1 | def gradient_descent(X,y,w,b,lr,iter): |
实现线性回归并调试参数
1 | iterations = 100 |
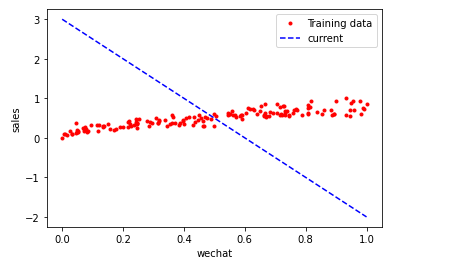
调整学习速率
如果损失函数和求导过程没有出现错误,一般造成损失过大的在于学习速率
通过比较学习速率和迭代次,选择最优
1 | loss_history,weight_history,bias_history = gradient_descent(X_train,y_train,weight,bias,alpha,iterations) |
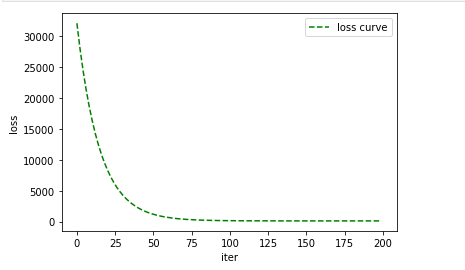
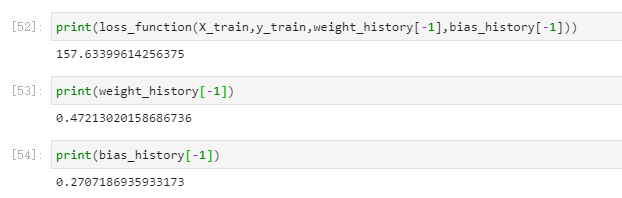
做完这一切也就是找到了最佳的两个参数
关于多元线性回归基于以上的同等道理
下面贴出代码如下:
1 | import numpy as np # 导入NumPy数学工具箱 |
其他代码
1 | from sklearn.linear_model import LinearRegression #导入线性回归算法模型 |
参考文章
https://blog.csdn.net/VariableX/article/details/107166602
使用岭回归和LASSO回归,主要针对自变量之间存在多重共线性或者自变量个数多于样本量的情况。