机器学习平凡之路一
- 一些概念
- 一些操作
- 基本的机器学习术语
- 机器学习项目结构
一些概念
机器学习是AI技术的分支,深度学习是机器学习的技术之一
机器学习的关键内涵在于利用计算机的运算能力从大量的数据中发现一个函数或者模型,通过她来模拟现实世界事物之间的关系,从而预测或者判断的功能
自变量在机器学习中叫做特征,也可以叫做标签。或者叫做标记也可以
比如:爸爸的身高(自变量X1),妈妈的身高(自变量X2),可能会影响孩子的身高(因变量y)
机器学习是在已知数据集的基础上,反复计算通过比较贴切的函数,找到之间的关系
机器学习中监督学习需要标签数据,无监督学习不需要标签数据,半监督学习介于2者之间
深度学习:就是层数较多,结构比较复杂的神经网络的机器学习,这个过程中会产生数据由非结构化到结构化的转变
注意:简单的说就是一张32px X 32px的图片通过深度学习转换为机器能够看明白的编码
强化学习:研究智能体如何基于环境做出行动反应,以取得最大化的累积奖励
机器学习两大场景
回归
回归问题通常用来预测一个值,标签的值是连续的
分类
分类问题是将事物标记一个类别的标签,结果为离散值,也就是类别中的一个选项
其它
聚类就是在没有便签的情况下,将数据按照特征的性质分成不同的簇
关联规则就是找到特征之间的影响关系
时间序列指内部结构随时间呈现规律性变化的数据集,类似金融市场,太阳活动等
机器学习不是万能的,只能作用于和已知数据集类似的数据,优势在于计算量,速度和准确性。暂时没有形成人类的智力思维模式
一些操作
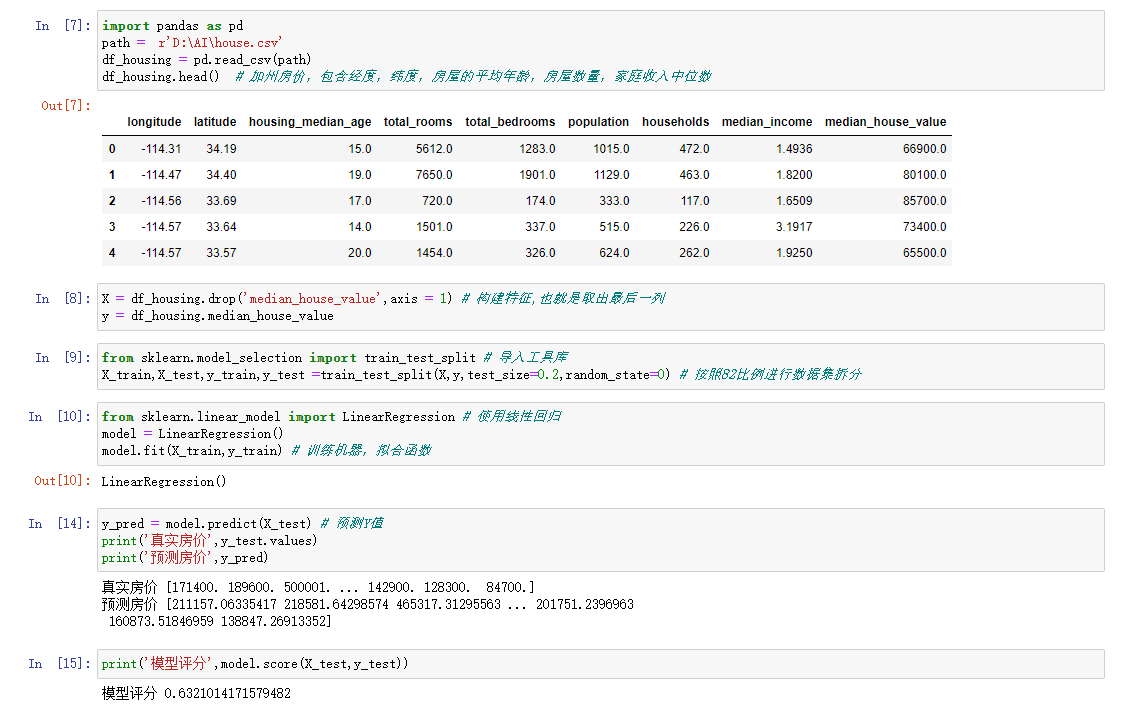
图形展示
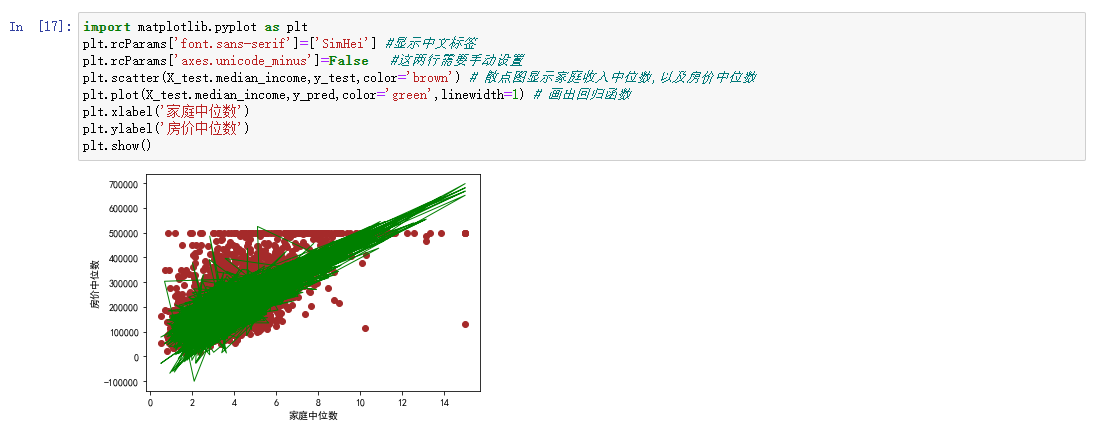
预测结果可以看到随着家庭的收入增高,房价也是随之水涨船高。
基本术语
| 术语 | 定义 | 数学描述 | 示例 |
|---|---|---|---|
| 数据集 | 数据的集合 | {(x1,y1),…,(xn,yn)} | 比如1000个房屋的面积,楼层,以及房价 |
| 样本 | 数据集中的一条具体记录 | (x1,y1) | 一个房屋的数据记录 |
| 标签 | 预测的结果也称作为目标 | y | 房价 |
| 有样本标签 | 特征,标签,用于训练 | (x,y) | 800个房屋信息 |
| 无标签样本 | 有特征,无标签 | (x,?) | 200个房屋信息不带房价 |
| 模型 | 样本的特征映射到预测标签 | f(x) | 通过特征信息确定房价的函数 |
| 模型中的参数 | 参数确定了机器学习的模型 | f(x) | f(x) = 3x+2中的3和2 |
| 模型的映射结果 | 通过模型获取到的无标签样本的标签 | y’ | 200个预测出来的房价 |
特征的维度指的是特征的数目,不同的数据维度有多有少,比如房屋面积就是特征,图片100px X 100px,每一个像素是一个特征,颜色通道有3个,那就是就3万个特征
标签就是机器学习要输出的结果
模型就是函数,就是执行预测的工具
机器学习项目结构
- 函数模型
- 评估函数的优劣
- 确定最优的函数
| 步骤一 | 步骤二 | 步骤三 | 步骤四 | 步骤五 |
|---|---|---|---|---|
| 问题的定义 | 数据的收集和预处理 | 模型的选择 | 选择机器学习模型 | 超参数调试和性能优化 |
问题的定义
可以按照痛点,现状,目标来进行思考
数据的收集和预处理
- 可视化:通过分析工具或者Excel对数据有一个基本的了解
- 数据向量化:把原始数据格式化,让机器变得可以读取。将文字转为one-hot编码,类别变为0,1
- 处理坏数据和缺失值
- 特征缩放自行百度
- 特征工程和特征提取也就是选择最有价值的特性
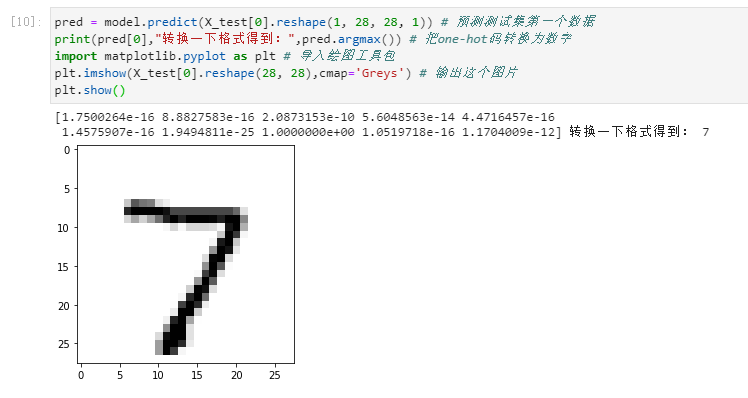
图像识别

注意:改变格式,是因为keras要求图像数据集导入卷积网络模型为4阶张量,最后一阶代表颜色深度,灰度图像只有一个颜色通道,设置值为1,one-hot编码请自行百度
选择模型
使用前先读https://blog.csdn.net/monk1992/article/details/89947267
2.0以下的版本
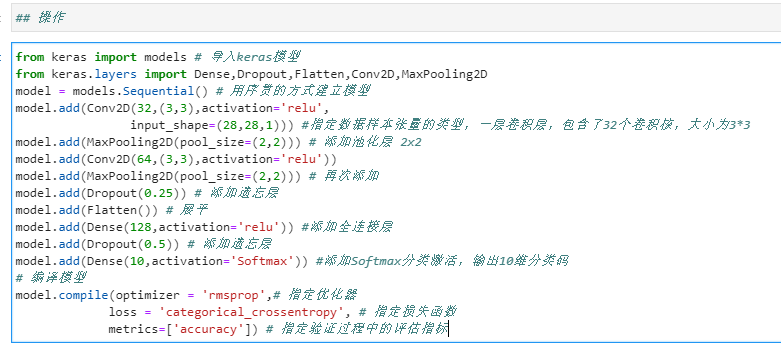
注意:以上代码包含2个2维卷积层,2个最大池化层,2个遗忘层,防止过度拟合.最后通过全连接层,通过分类器输出预测标签
最新版本的代码参考
1 | import tensorflow as tf |

训练机器,确定参数
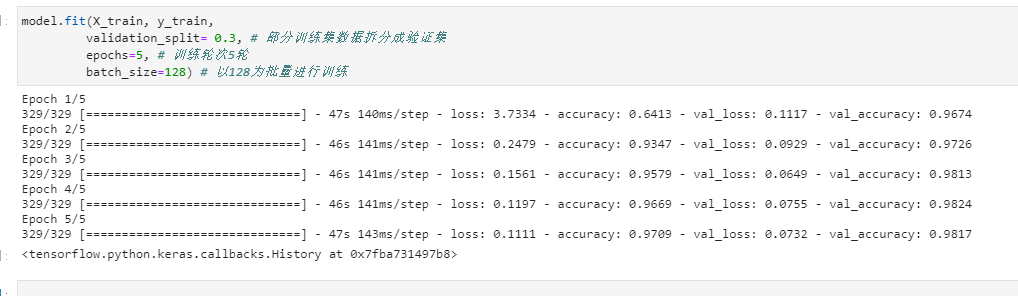
通过训练可以看出accuracy代表训练集上的预测准确率,val_accuracy代表验证集上的预测准确率
关于超参数调试和性能优化
- 机器学习重在评估
- 机器训练的过程,对于模型内部参数的评估是通过损失函数进行的
- 机器训练结束后,还要进行验证。现在是指明使用accuracy,使用分类的准确率做为验证指标
- k折验证将数据划分为大小相通的k个分区。每个分区打出的分数取平均分数。