通过将数据进行分组以及聚合,能够更加能够看到数据的重要性,越来越接近我的想法了.
数据聚合和分组操作
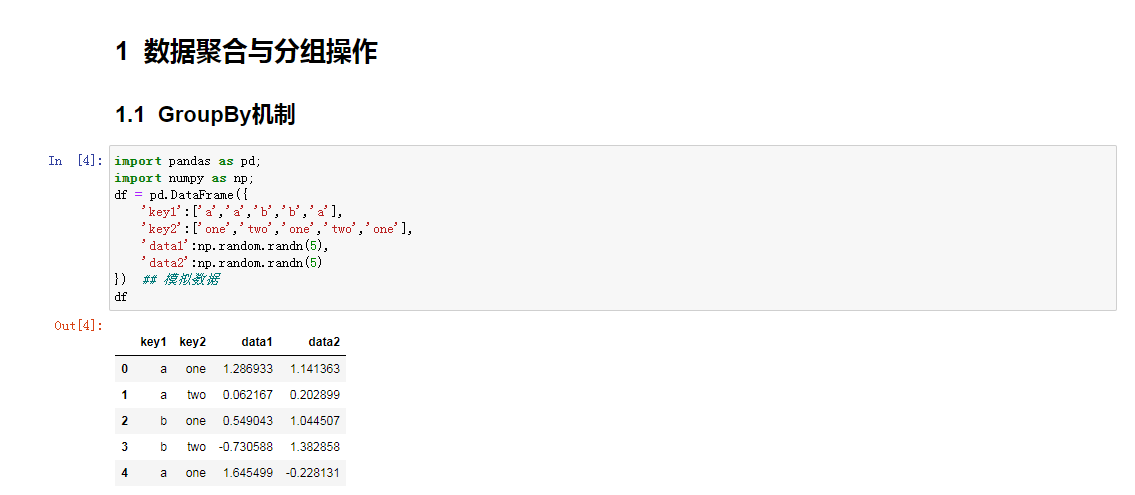
对数据及进行分类,在每一组数据应用聚合函数或者转换函数,这是非常重要的一个部分.一般在数据载入,合并,准备数据集之后,可能需要计算分组统计或者数据透视表用于报告或可视化的目的。pandas提供一个灵活的groupby接口,允许一种自然的方式对数据集进行切片,切块和总结。
我们可以通过pandas对象或者Numpy数据执行复杂的组操作
1. 使用一个或者多个键将pandas对象拆分为多块
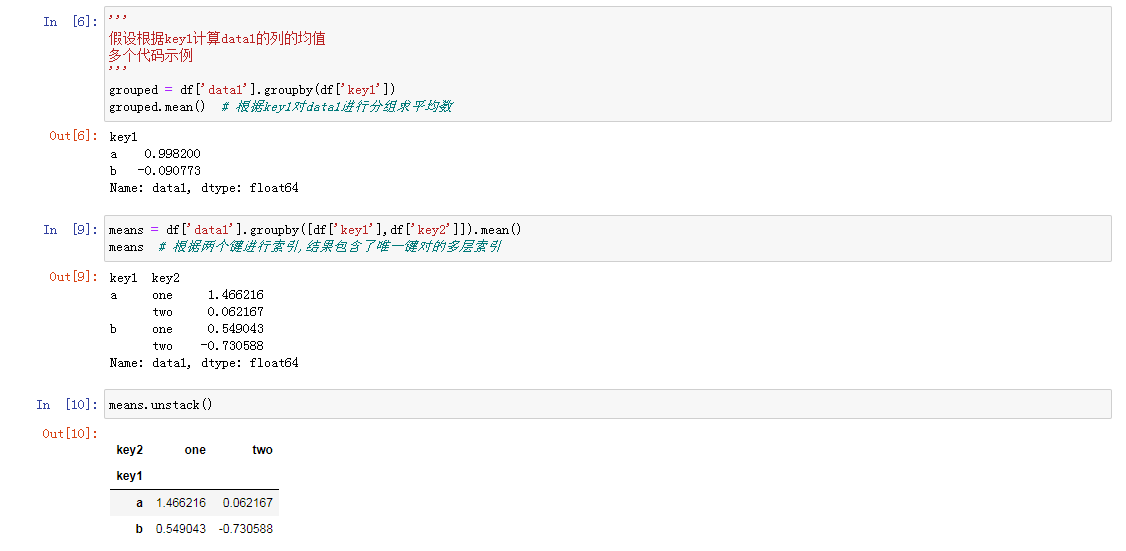
2. 计算组汇总统计信息以及应用组内变化或其他操作
3. 计算数据透视表和交叉表
4. 执行分位数分析以及其他统计组分析GroupBy机制
一般聚合操作中所有的动作为拆分-应用-联合,数据包含在pandas对象中,可以是不同的数据结构.之后可以根据一个或者多个键分离到各组中,可以沿着行或者列.分组操作后,一个函数就可以应用到各个组中,产生新的值。
注意:axis=0 代表着以行为单位从上至下计算,axis=1代表着以列为单位从左至右计算
分组键
分组键可以是多种形式的,不一定是完全相同的类型:
- 与需要分组的轴长度一致的值列表或者值数组
- DataFrame的列名的值
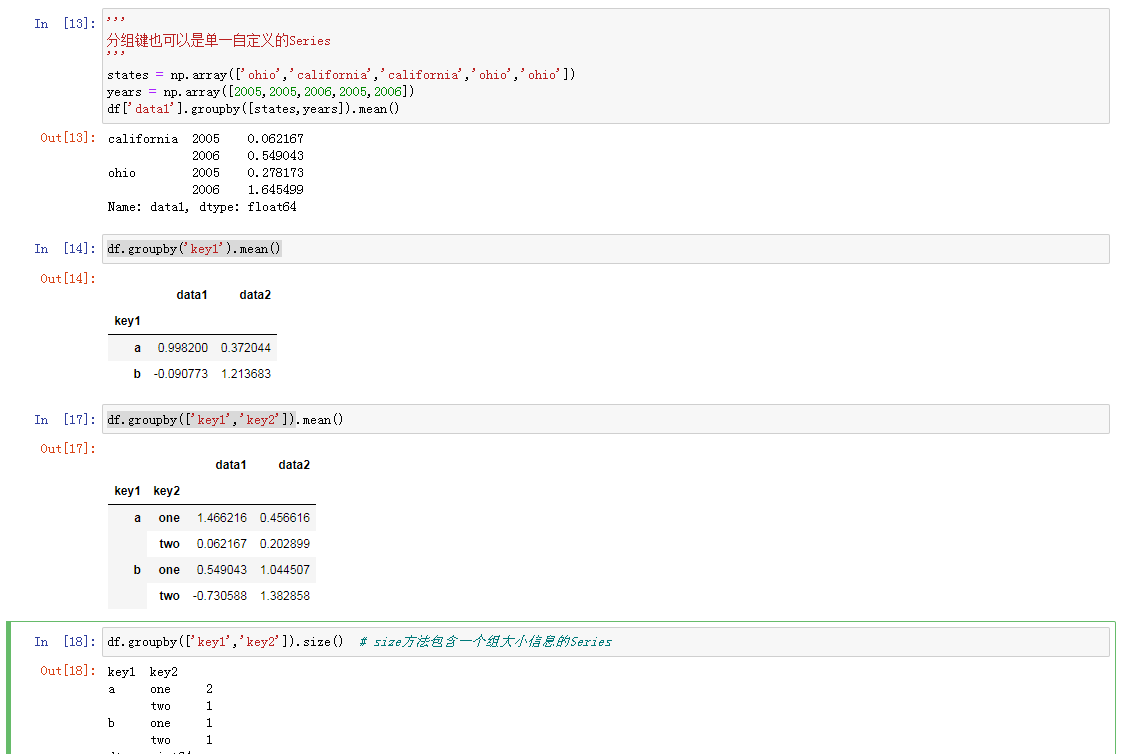
- 可以将分组轴向上的值和分组名称相匹配的字典或者Series
- 可以在轴索引或者索引中单个标签上调用的函数
示例说明
遍历分组对象
group对象支持迭代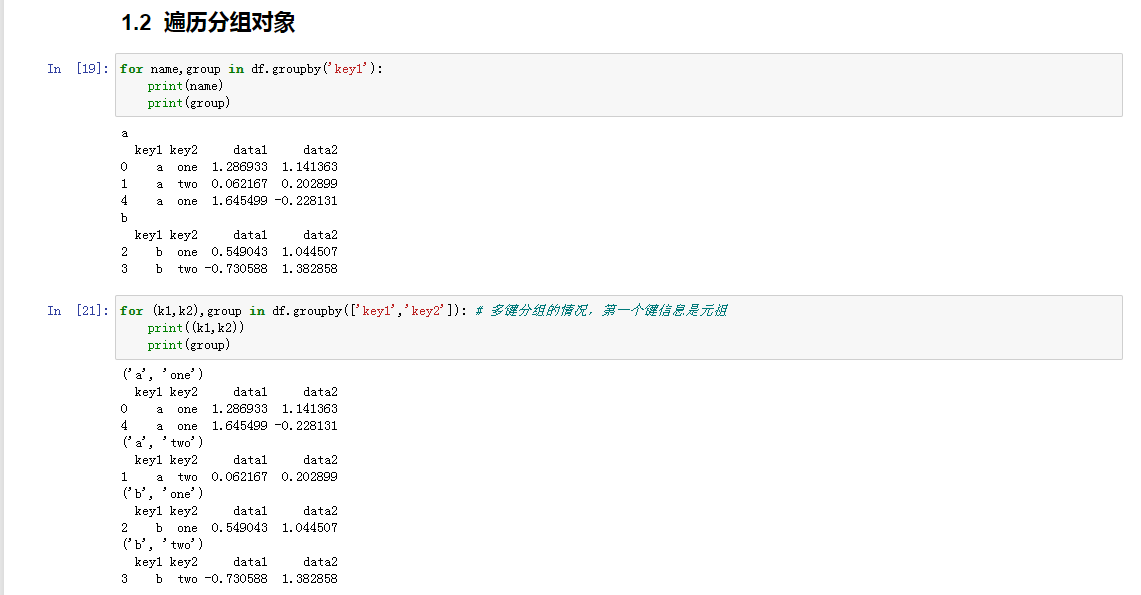
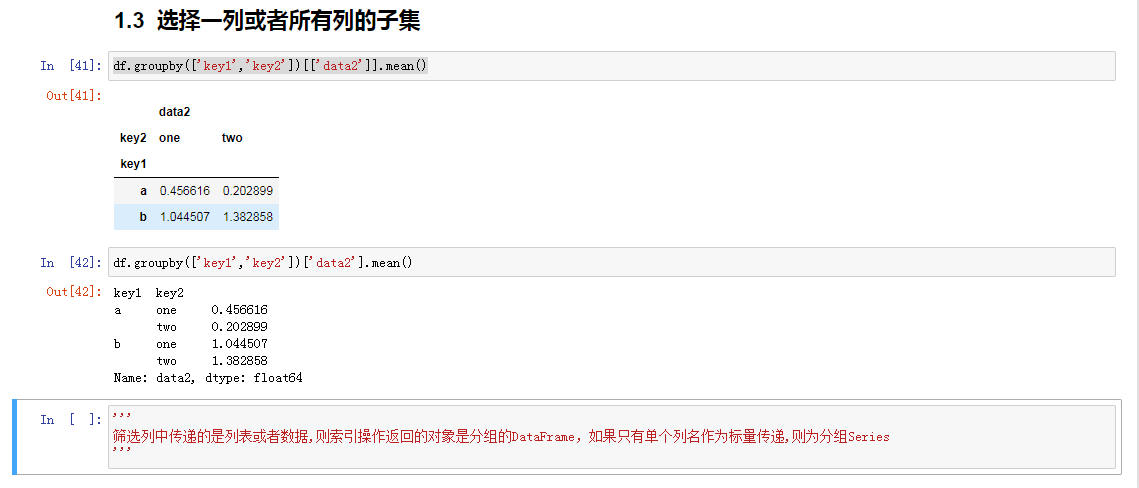
选择一列或者所有列的子集
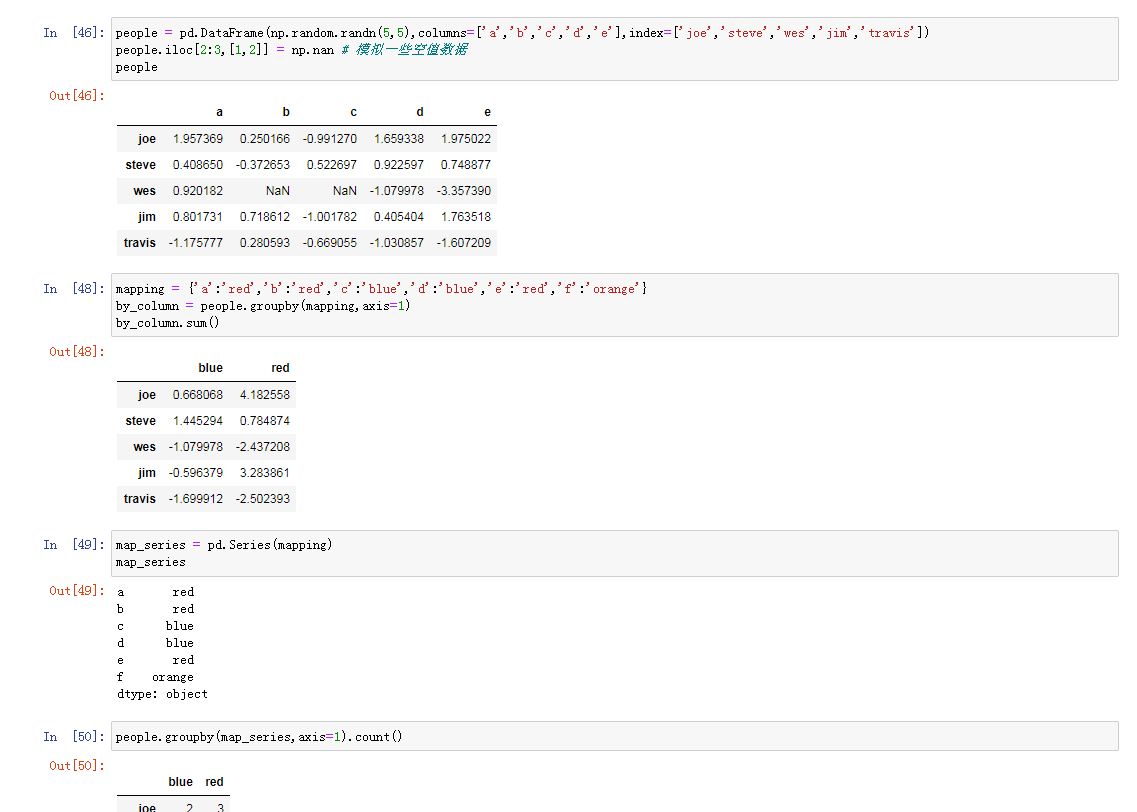
使用字典和Serise进行分组
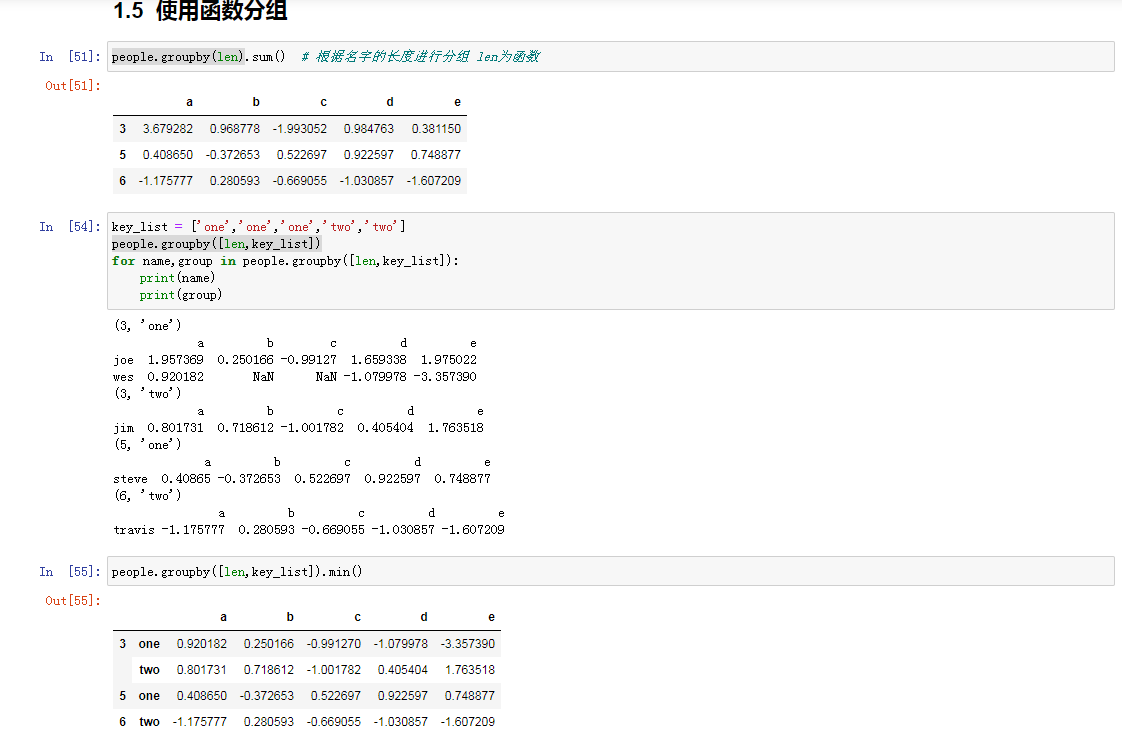
使用函数分组
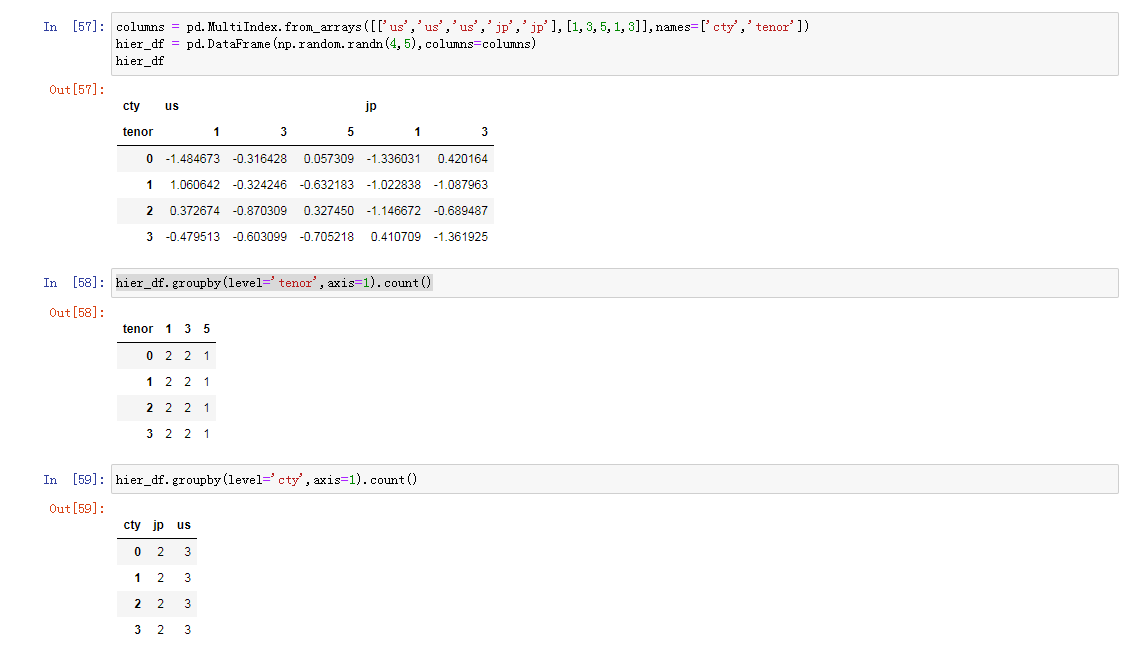
根据索引层级进行分组
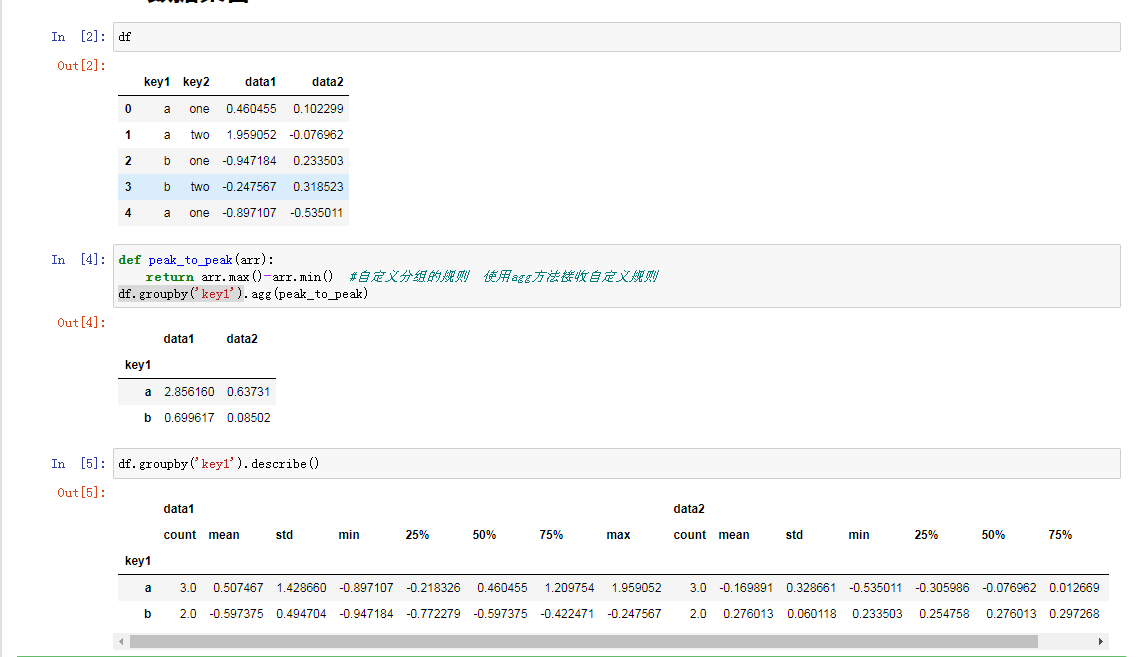
数据聚合
聚合是指所有根据数组产生标量值的数据转换过程,也就是类似统计函数一样.
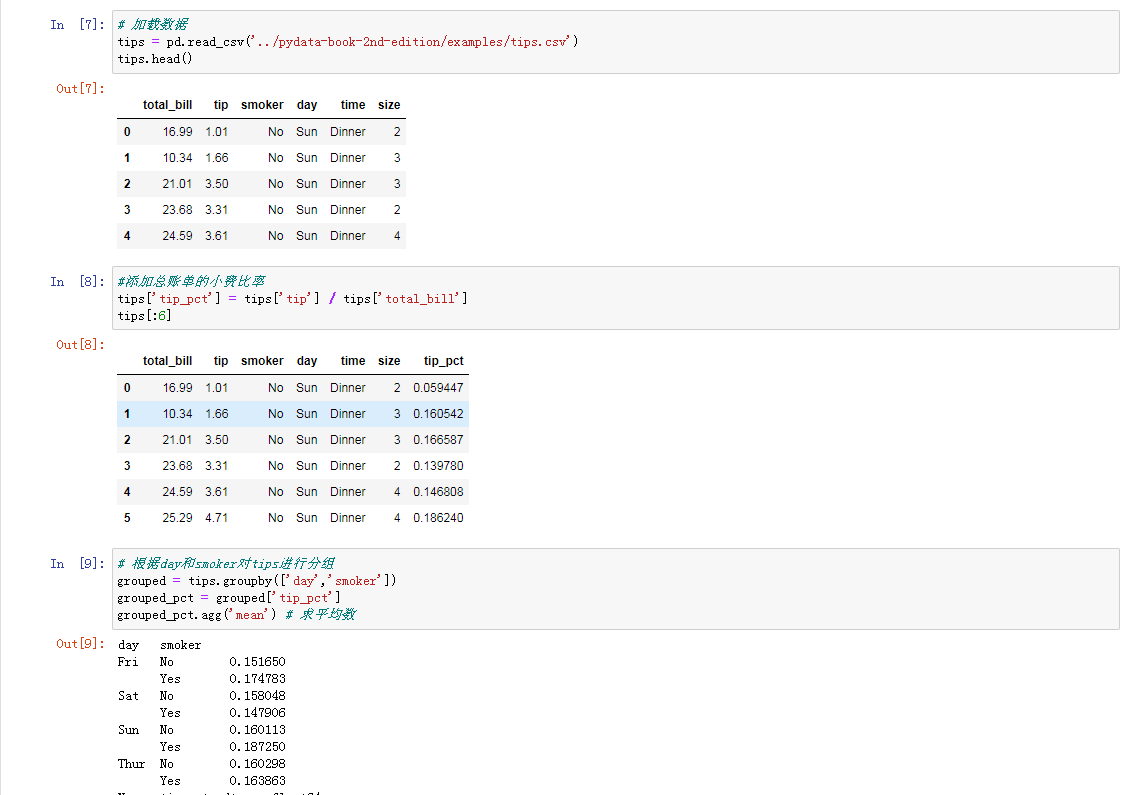
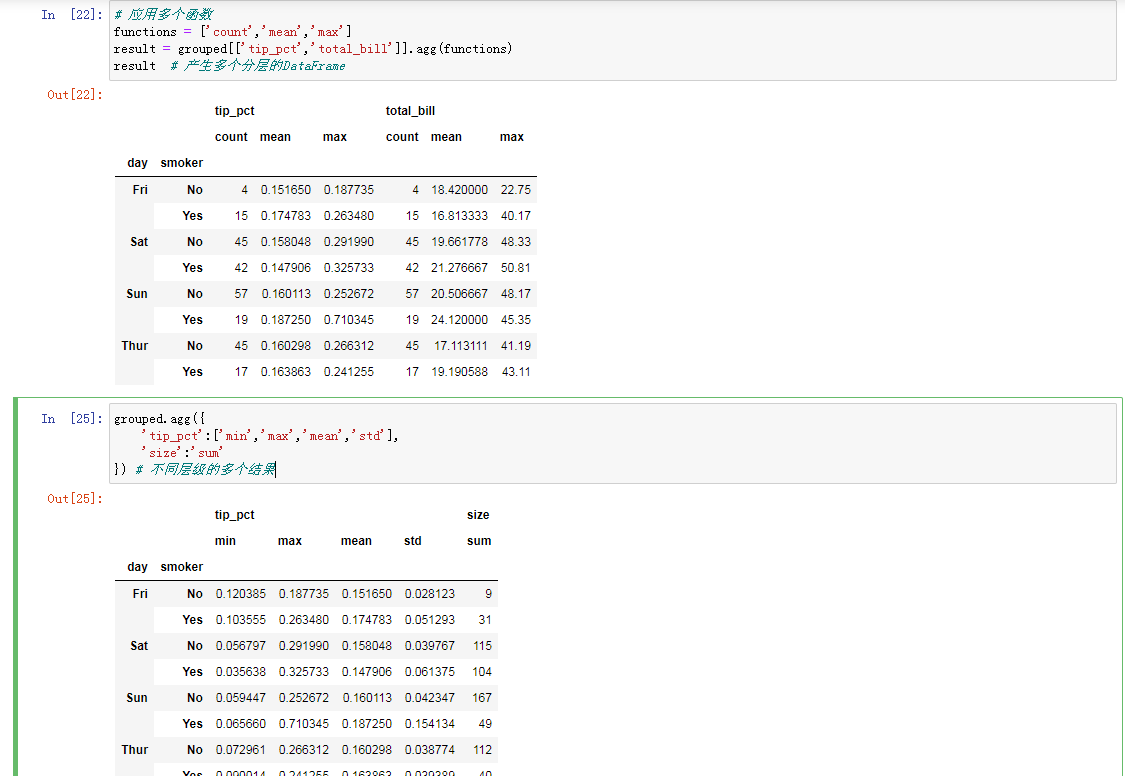
逐列以及多函数应用
不同的操作方式0
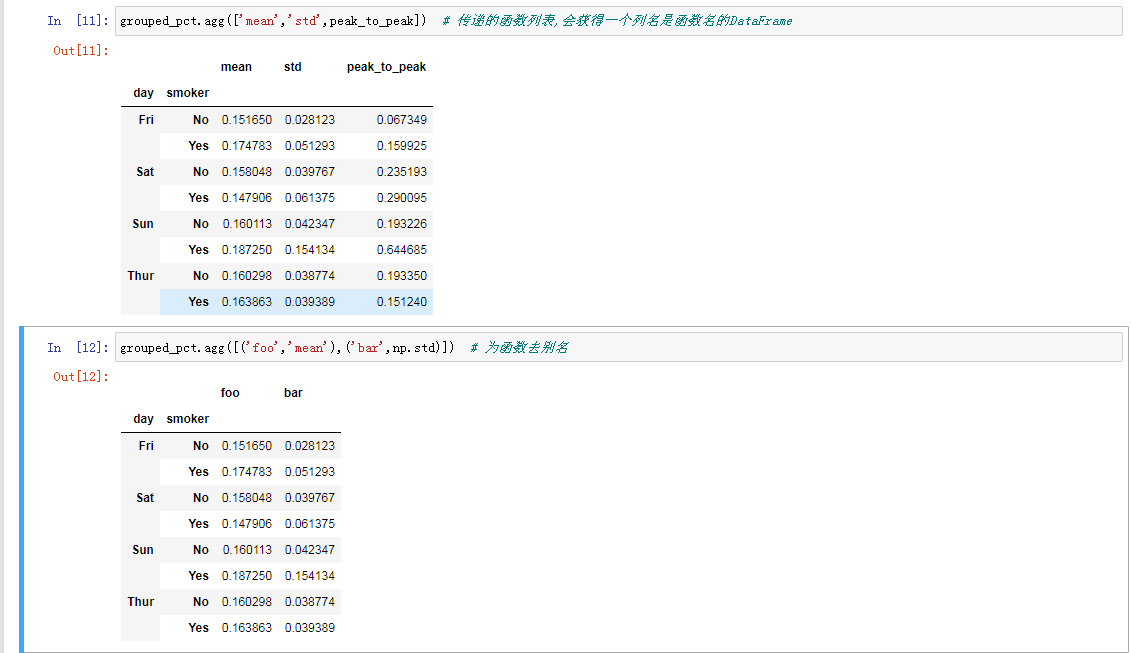
不同的操作方式1
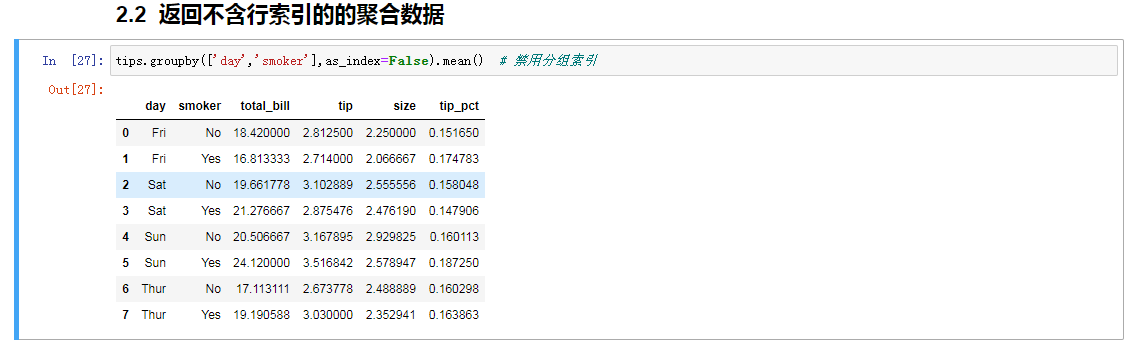
返回不带行索引的聚合数据
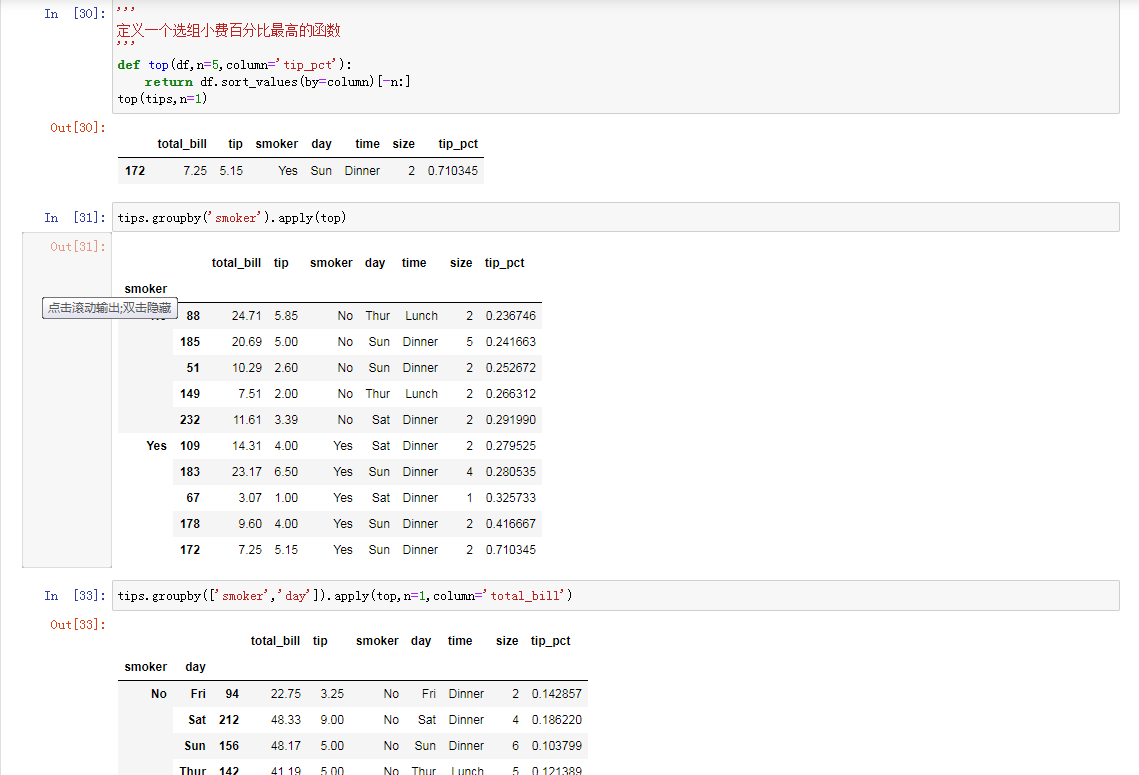
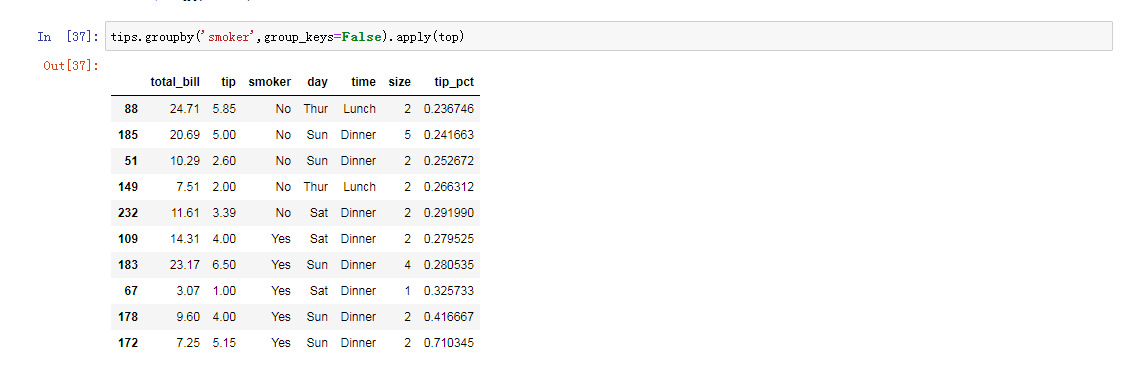
apply应用:通用拆分-应用-联合
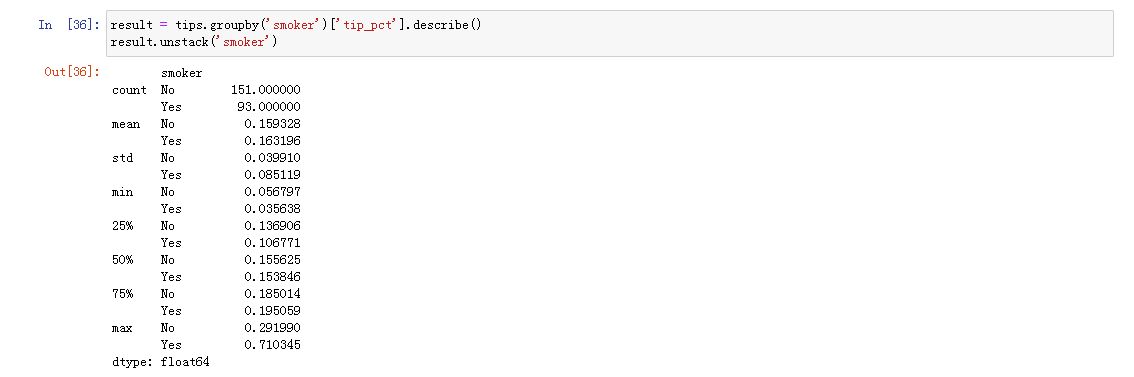
压缩分组键
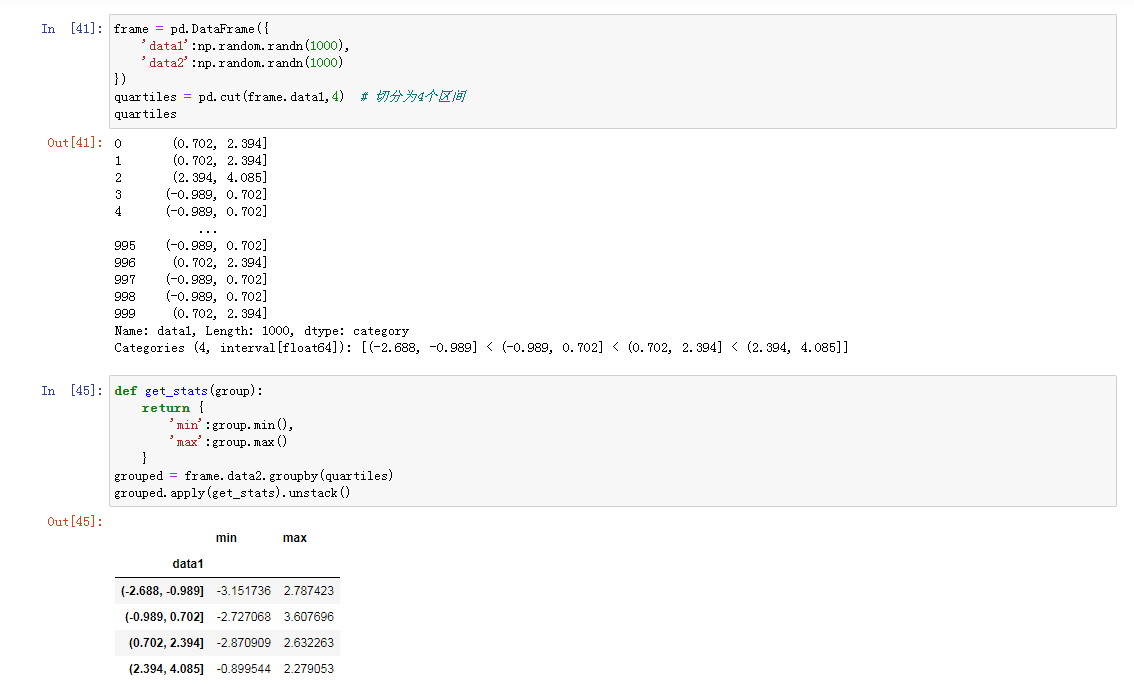
分位数以及桶分析
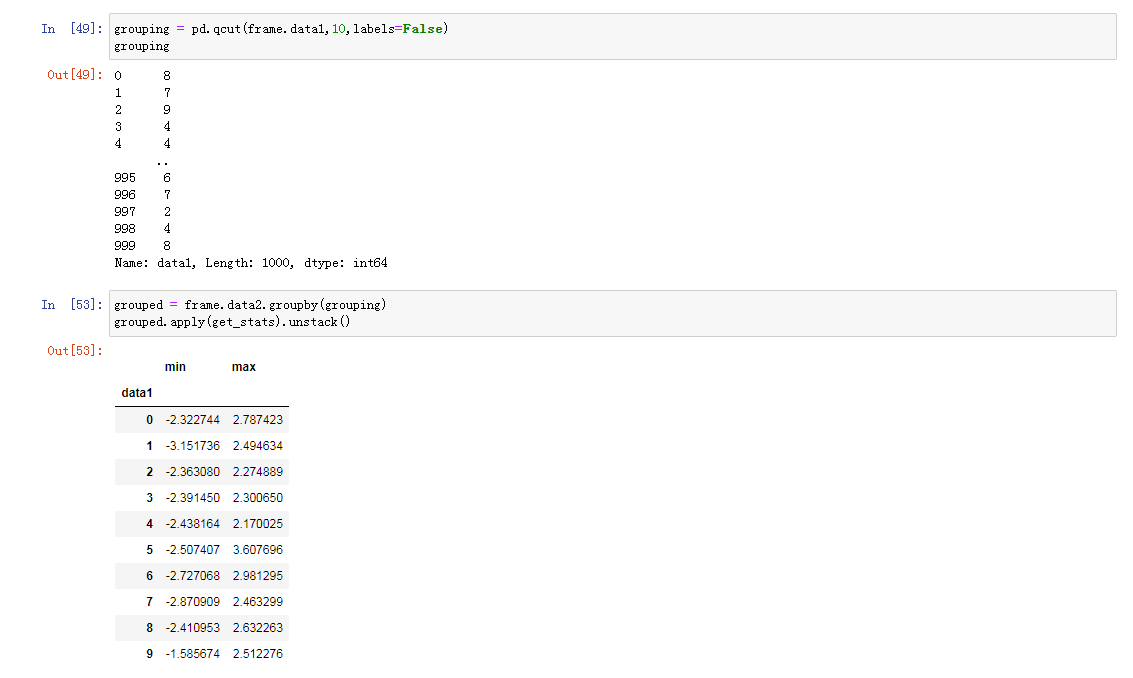
根据分位数
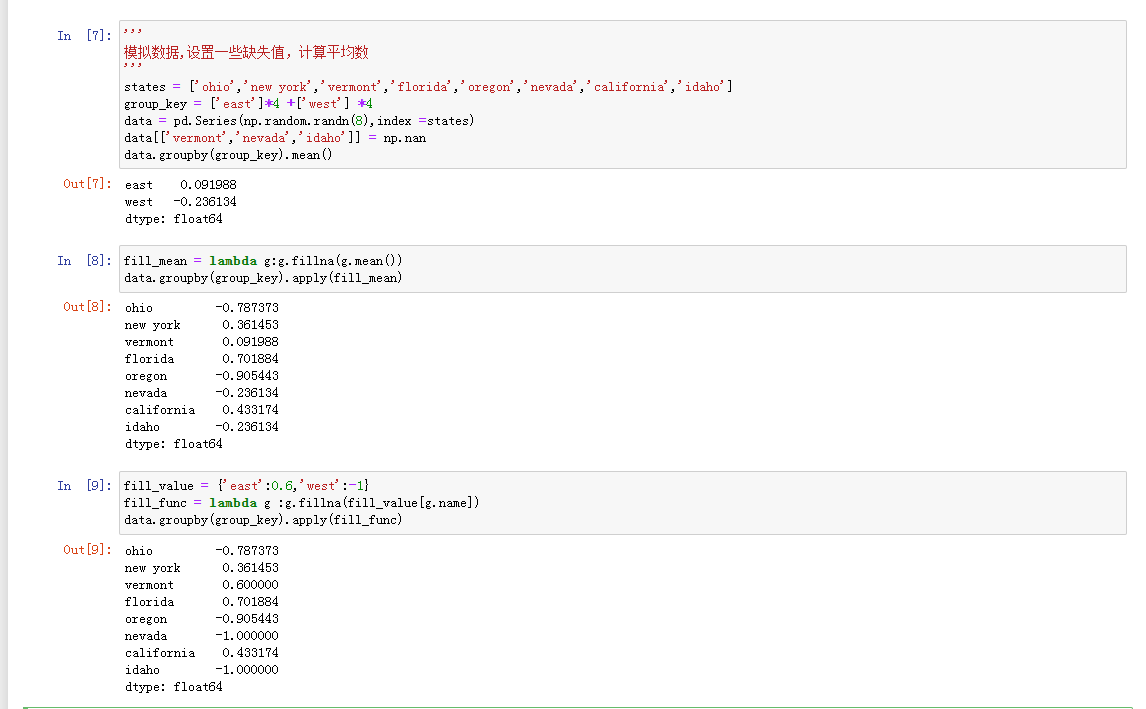
使用指定分组值填充缺失值
在清除缺失值,有时候可以用dropna去除缺失值,有时候可能需要进行修正.fillna是一个可以填充缺失值的方法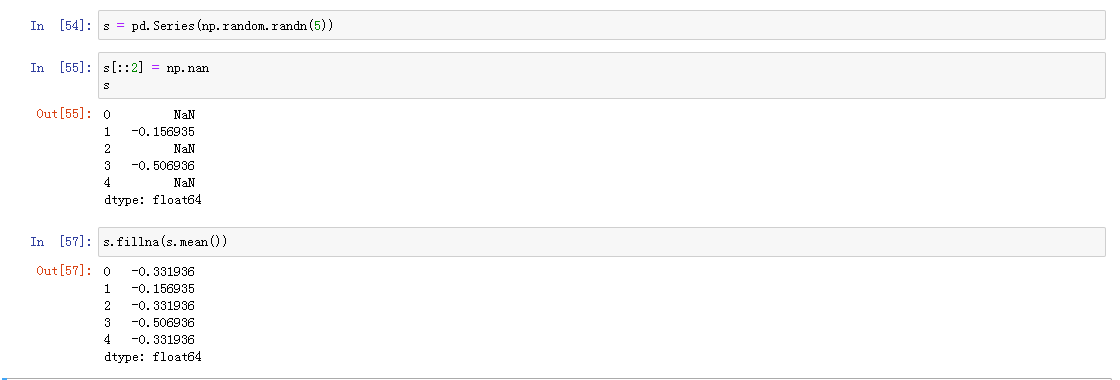
其他示例
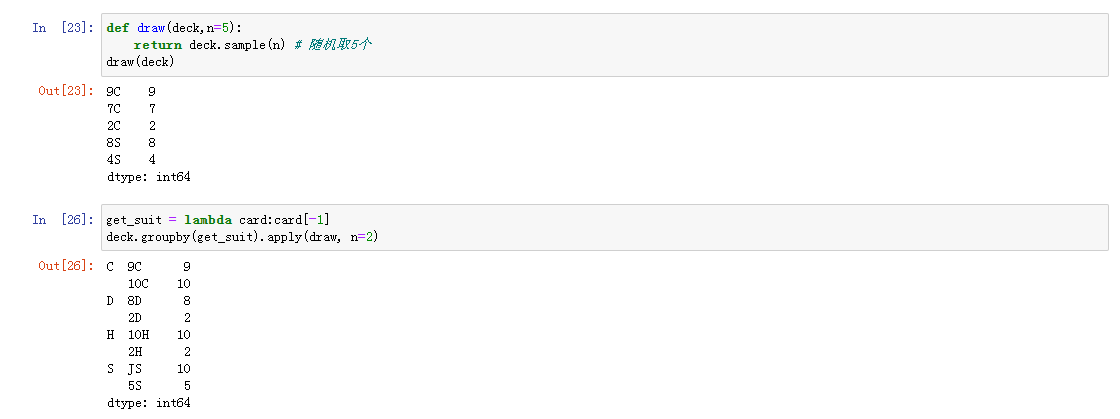
随机采样和排列
在Series中有sample方法可以帮助我们进行随机采样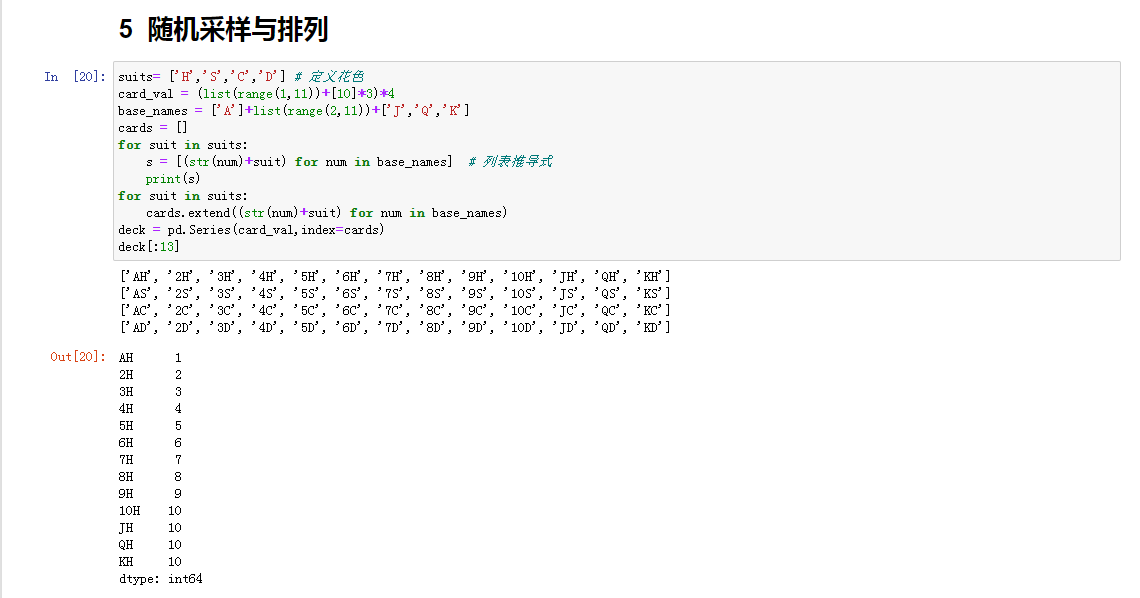
分组加权平均和相关性
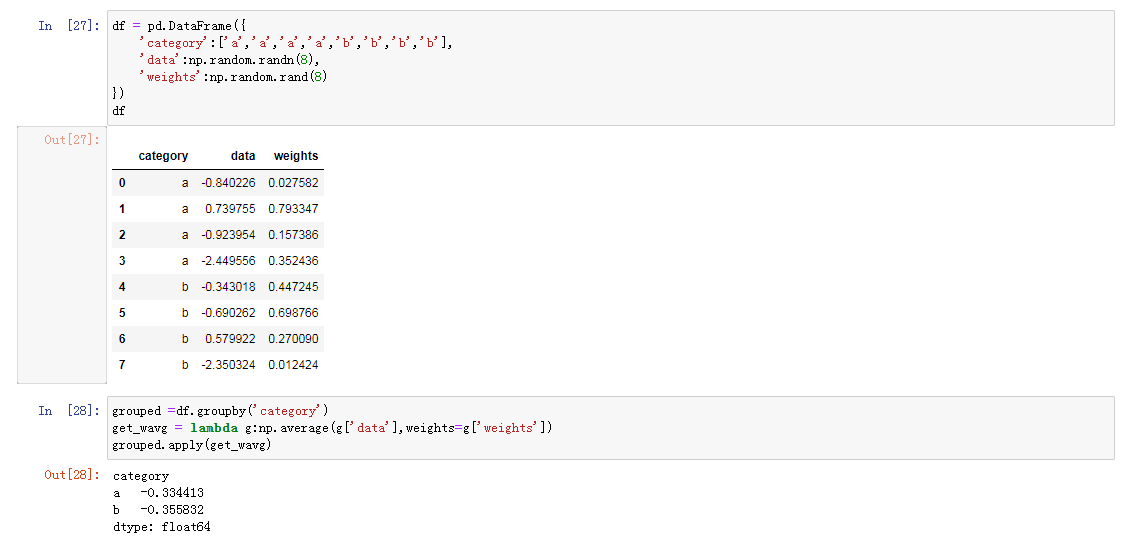
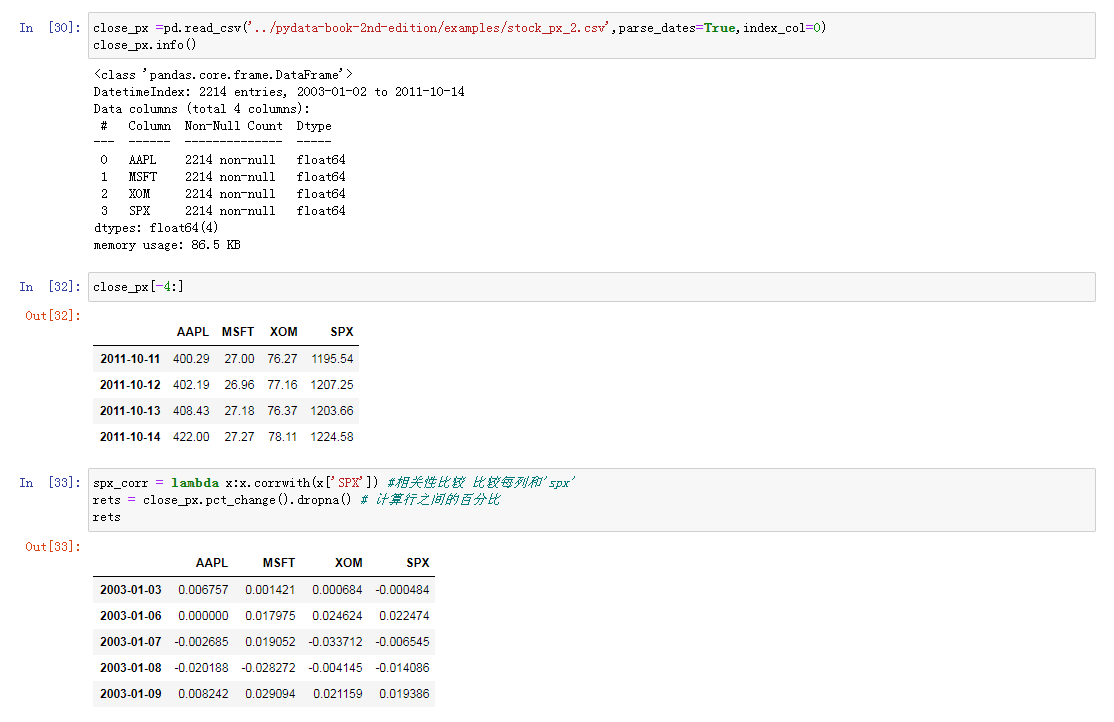
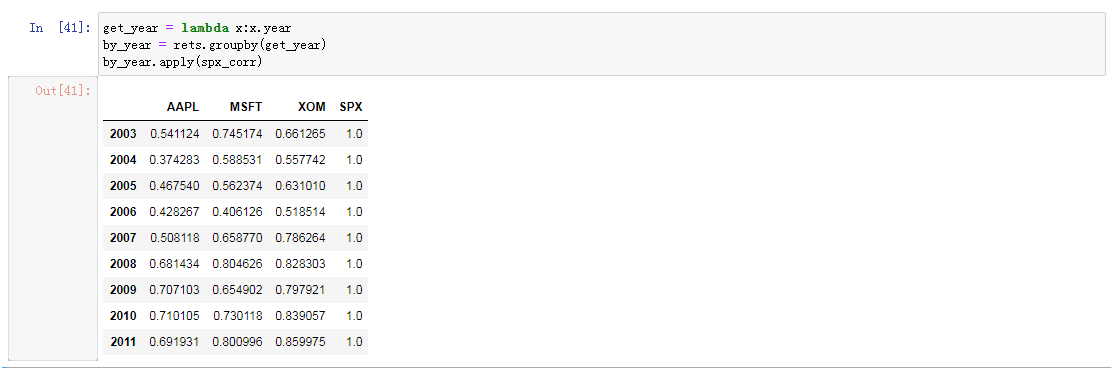
相关示例

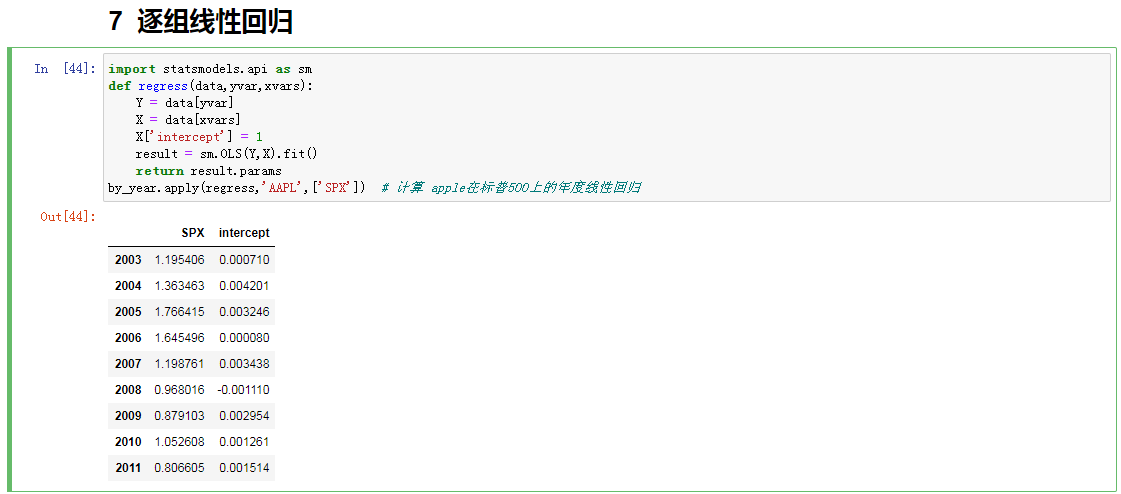
逐组线性回归(了解)
数据透视表和数据交叉表
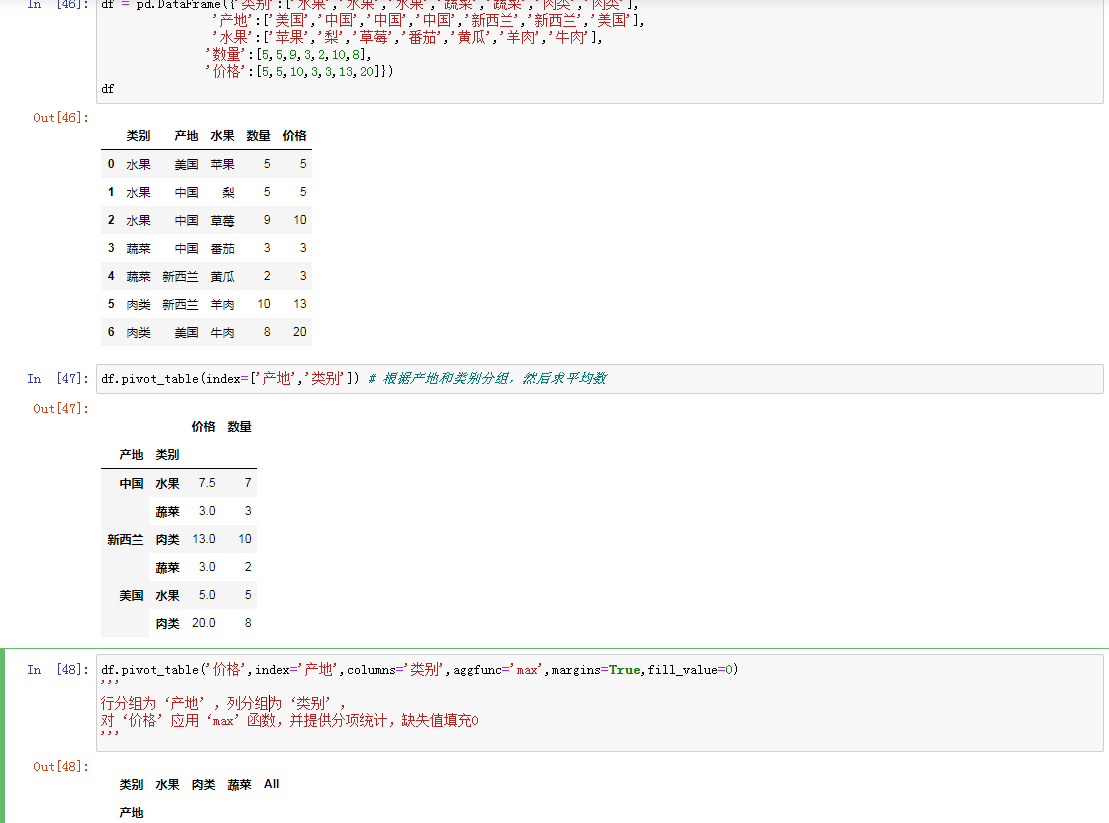
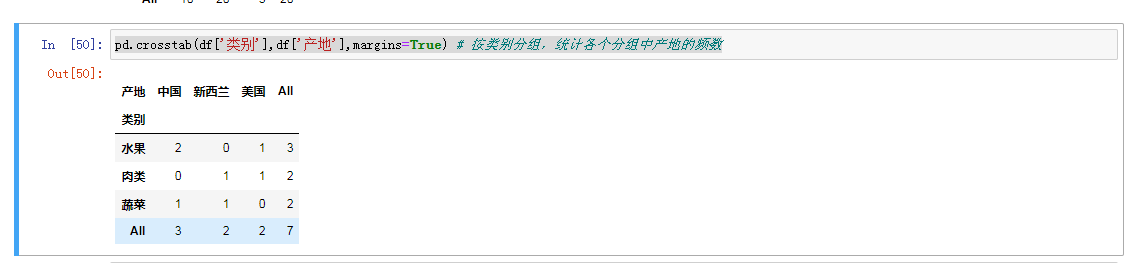
交叉表是用于统计分组频率的特殊透视表