这章可以在以后的数据分析案例中,慢慢的体会。但最终的目的就是为了组装自己想要的数据
数据规整之连接,联合与重塑
首先数据可能分布在多个文件或者数据库中,或以某种不易于分析的格式进行排列。而现在我们要做的就是如何连接,联合与重塑
分层索引
分层索引是pandas的重要特性,允许在一个轴向上拥有多个索引层级。分层索引提供了一种在更低维度的形式中处理更高维度数据的方式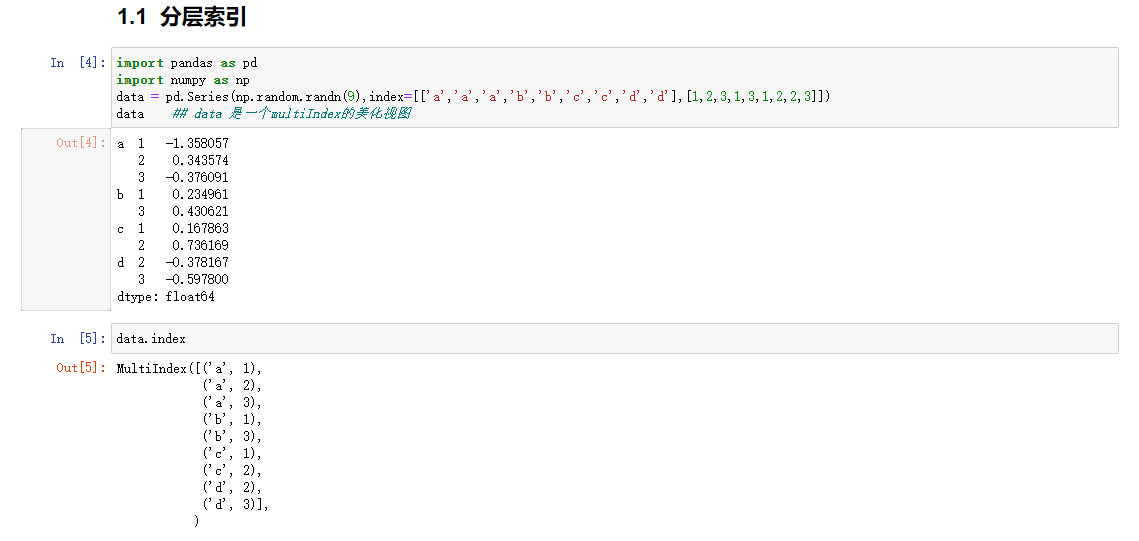
筛选数据子集
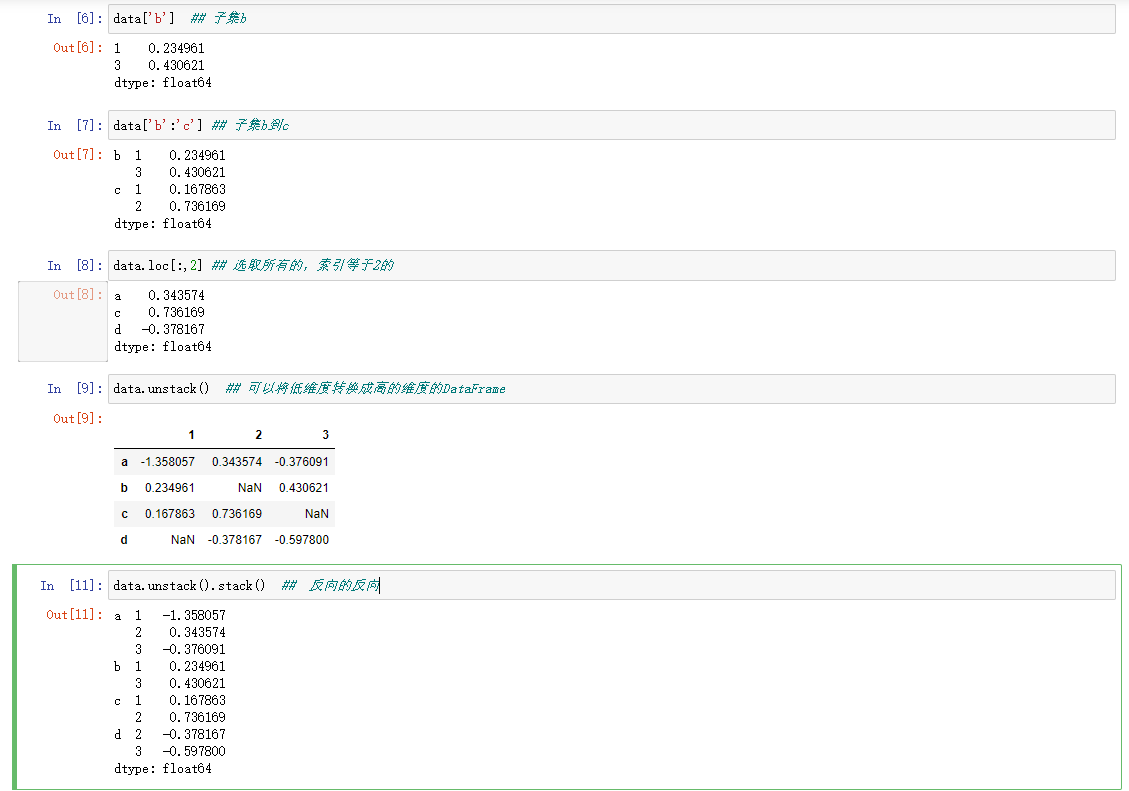
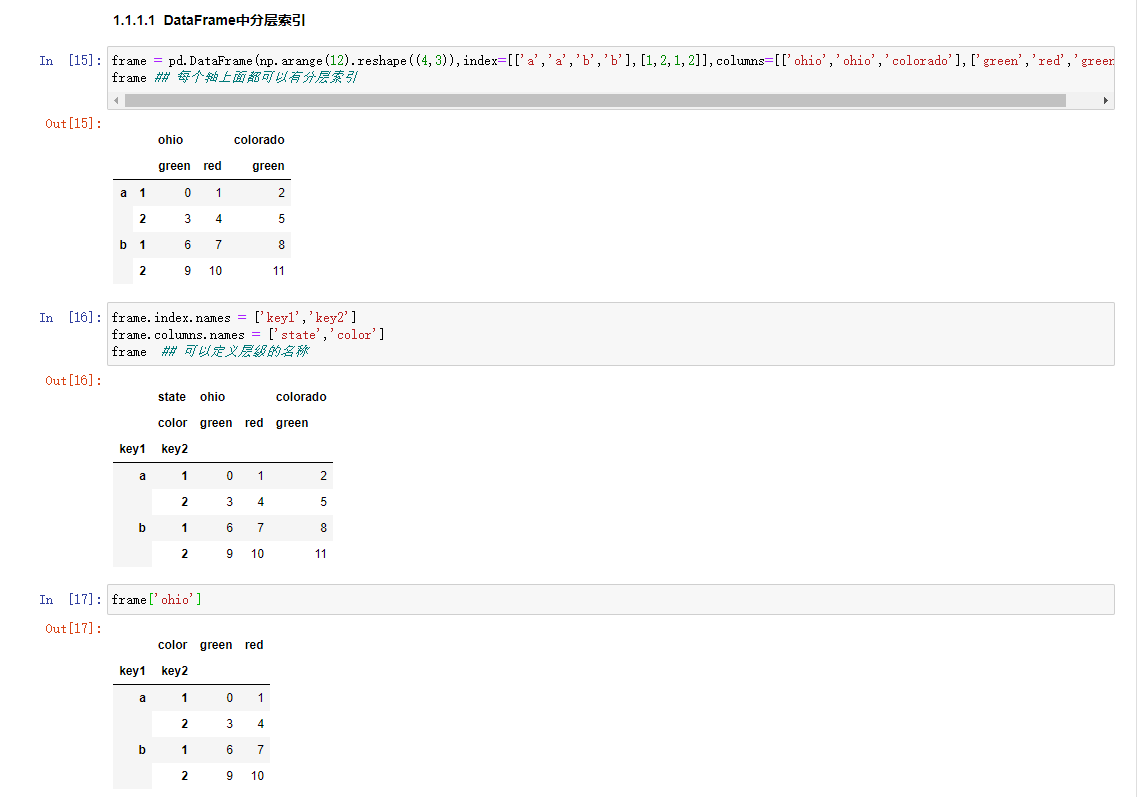
DataFrame中分层索引
重排序和层级排序
有时需要重新排列轴上的层级顺序,或者按照特定的层级对数据进行排序。使用swaplevel接收两个层级序号或者层级名称。返回一个层级变更的新对象,但是数据是不变的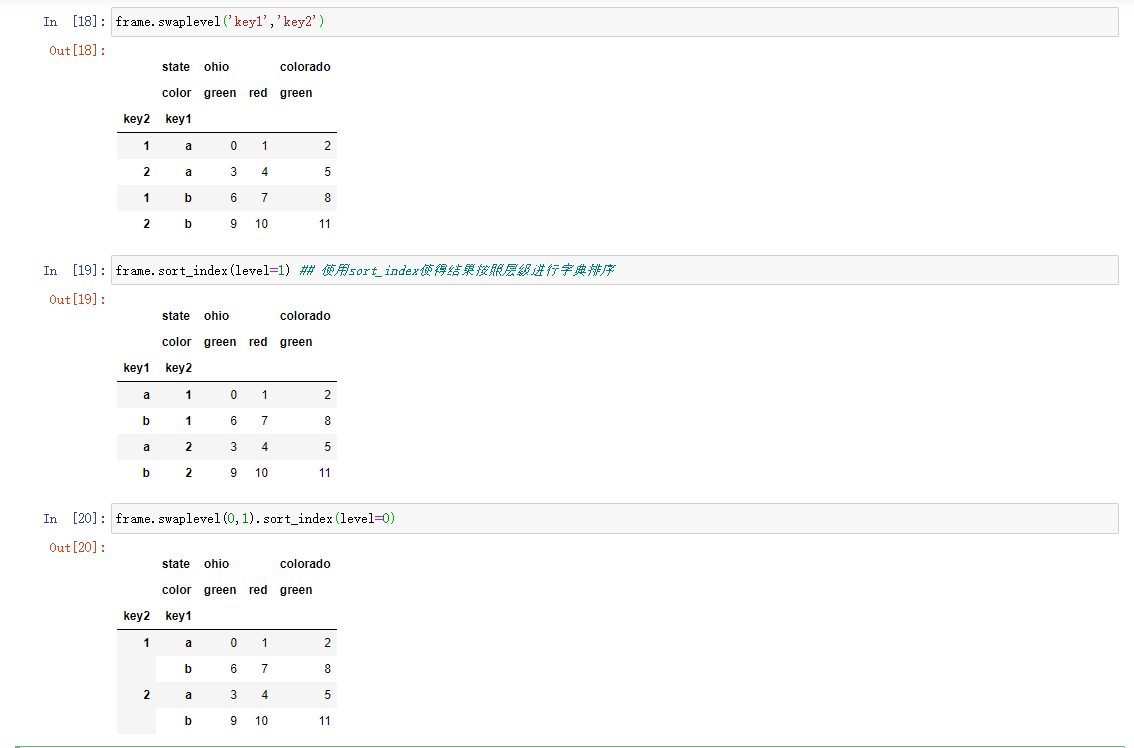
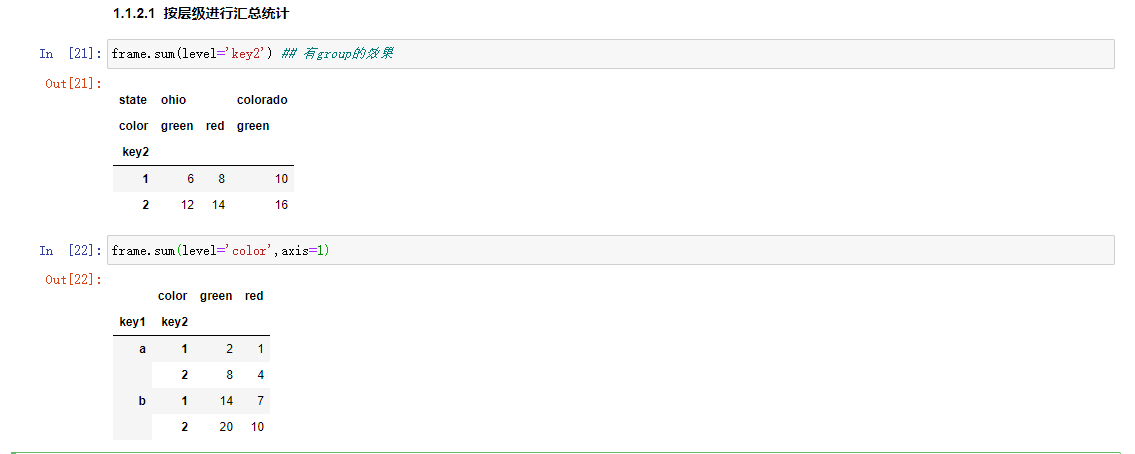
按层级进行汇总统计
DataFrame和Series有一个level选项。可以在某个特定的轴上面进行聚合
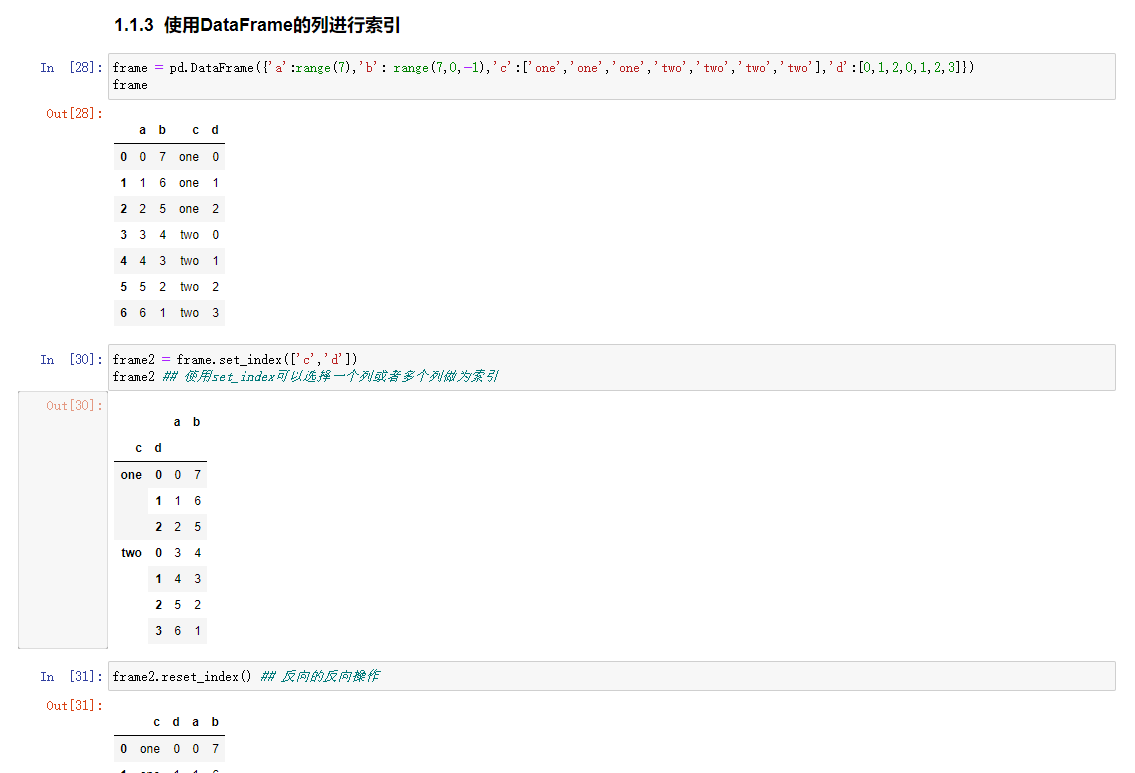
使用DataFrame的列进行索引
联合与合并数据集
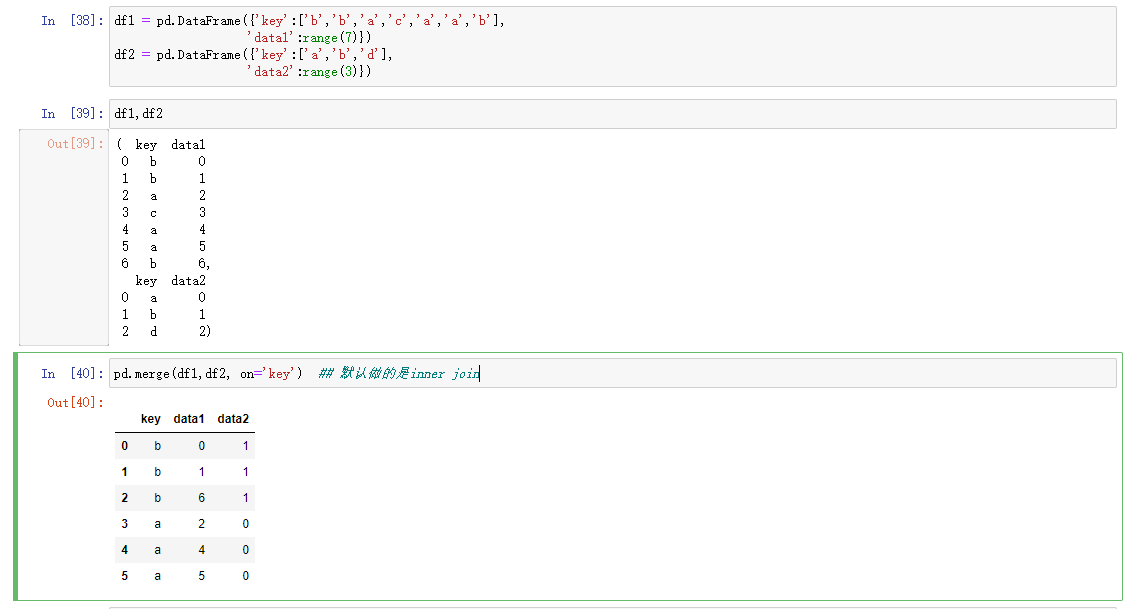
- pandas.merge可以根据一个或者多个键进行连接。
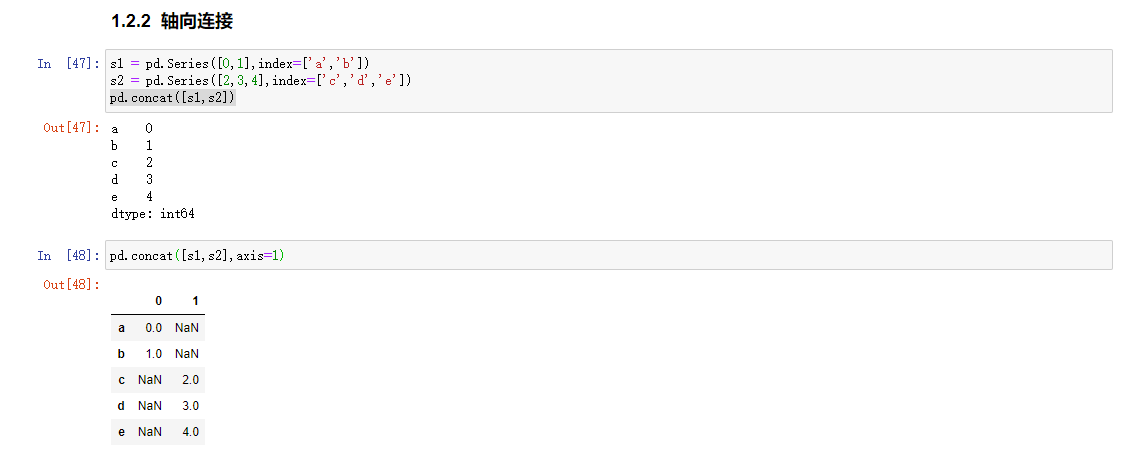
- pandas.concat是对象在轴向上进行黏合或堆叠
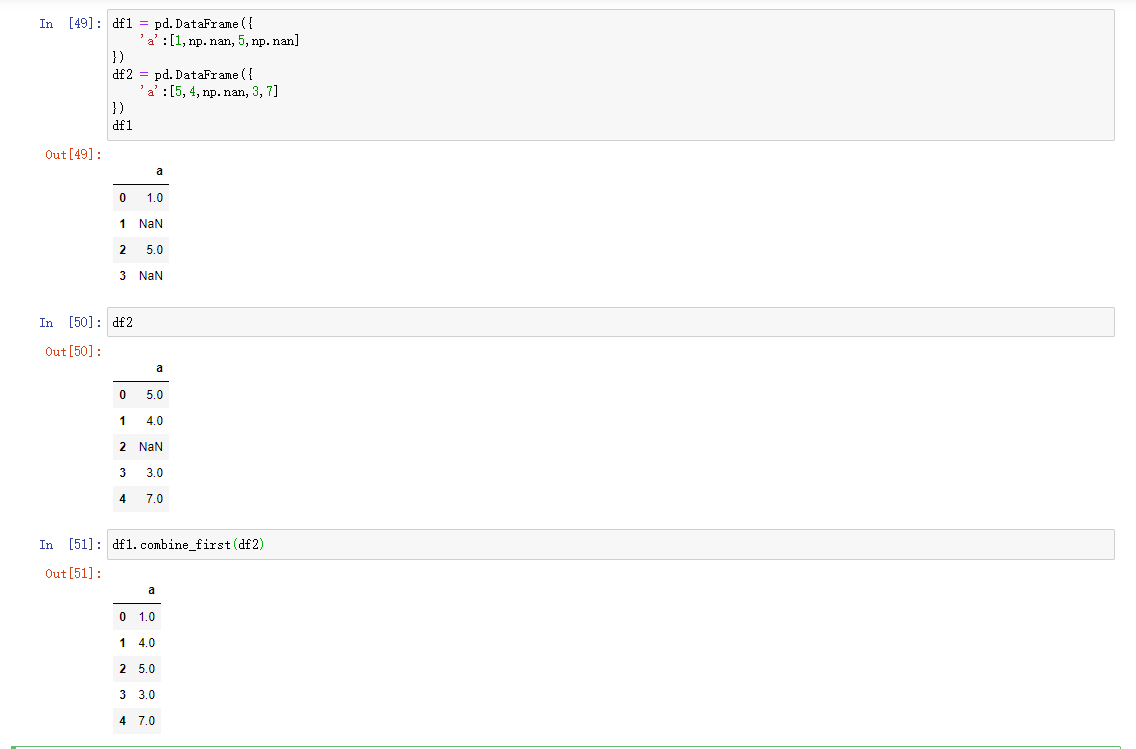
- combine_first允许将重叠的数据拼接在一起。以使用一个对象中的值填充另一个对象中的缺失值
数据风格的连接
左右连接以及outer并集
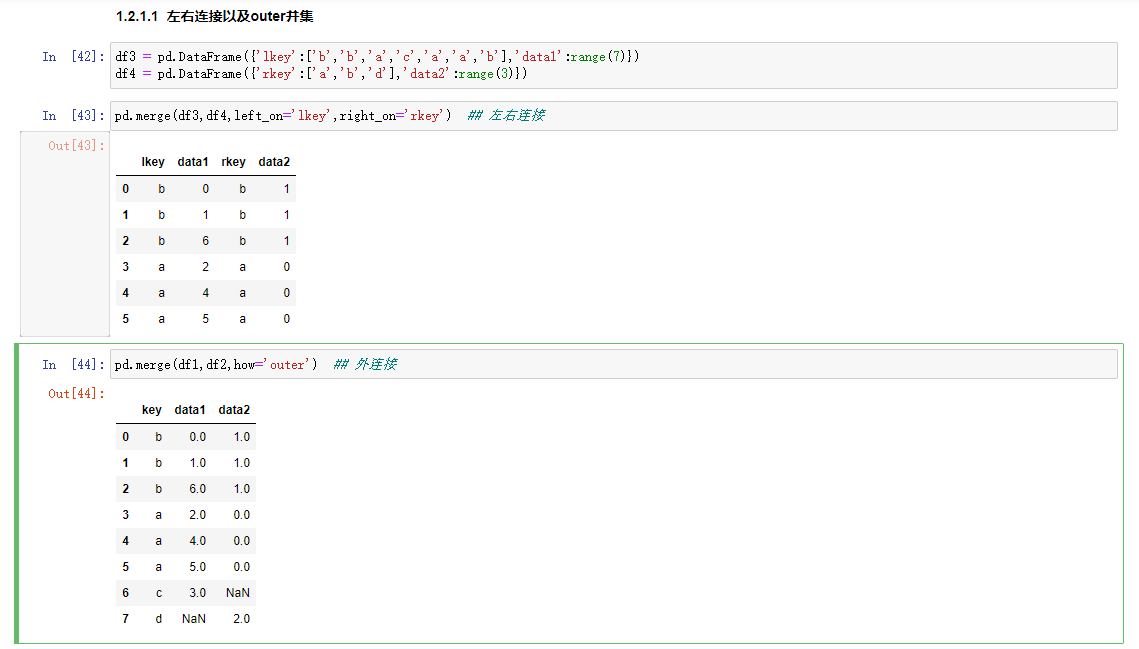
注意事项
多对多连接是行的笛卡尔积,使用多个键进行合并时传入一个列名的列表即可,在处理重叠的列名的时候可以使用suffixes进行重新命名
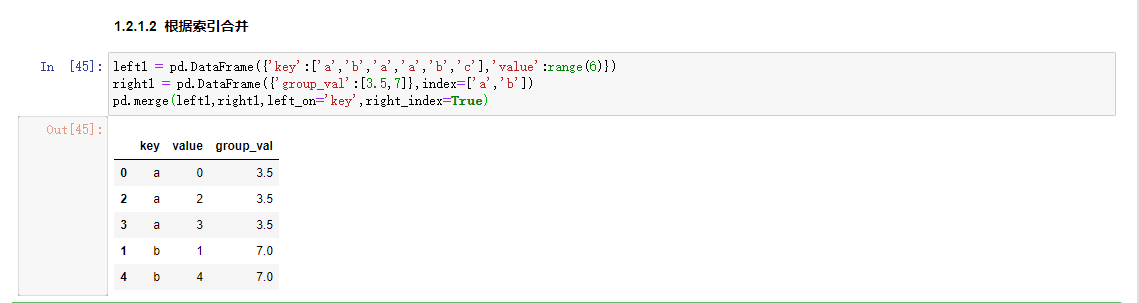
根据索引合并
沿轴向连接
一个是通过Numpy的concatenate函数,也可以使用pandas的concat函数
联合重叠数据
可以理解为填补Series或者DataFrame的缺失值,使用Combine_first
重塑和透视
多层索引在DataFrame中提供一种一致性的方式用于重排列数据。
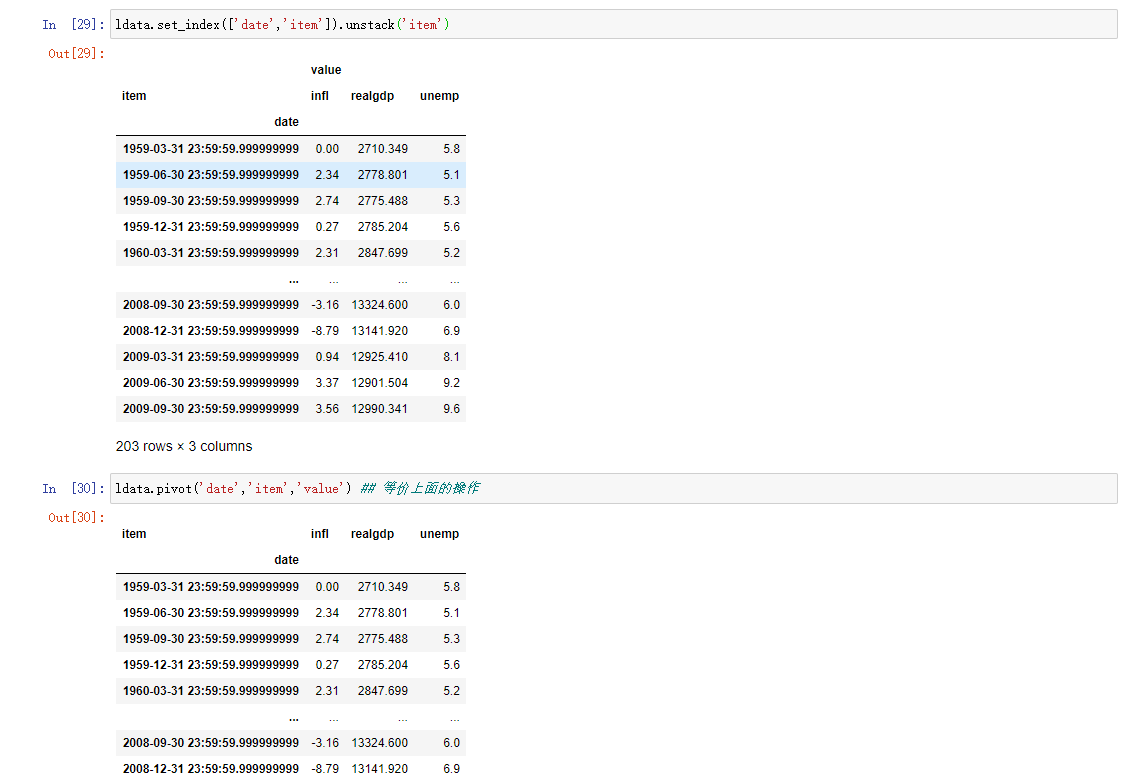
- statck简单的说就是转为低维度多层级的Series(堆叠) 也可以叫做列中的数据透视到行
- unstack简单的说就转为层级感强烈的DataFrame(拆堆) 也可以叫做行中的数据透视到列
长变宽
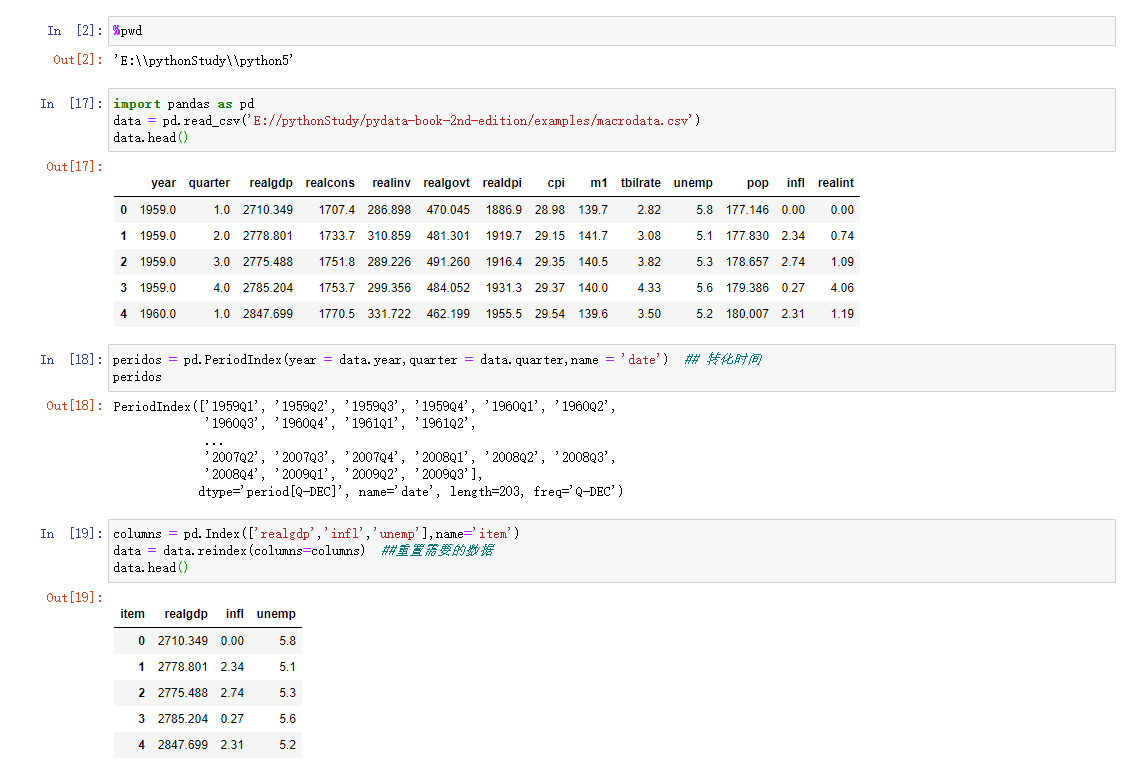
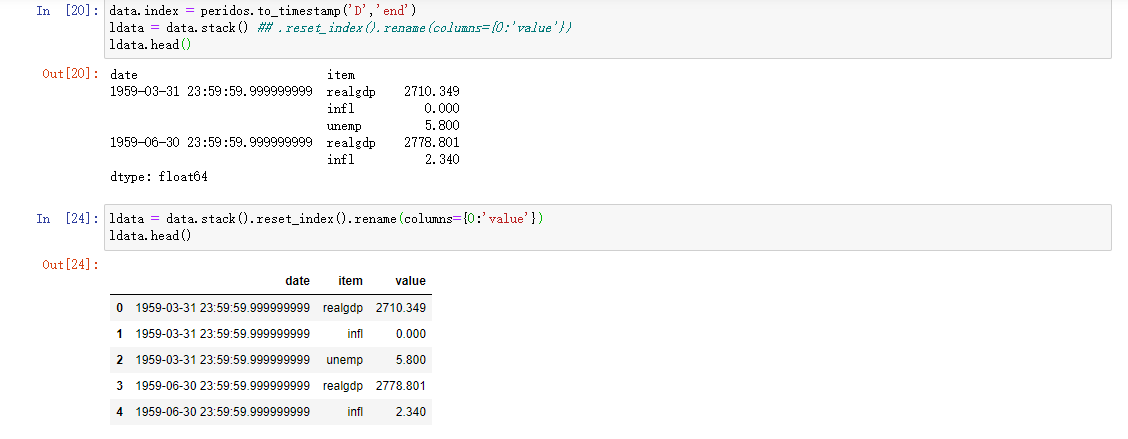
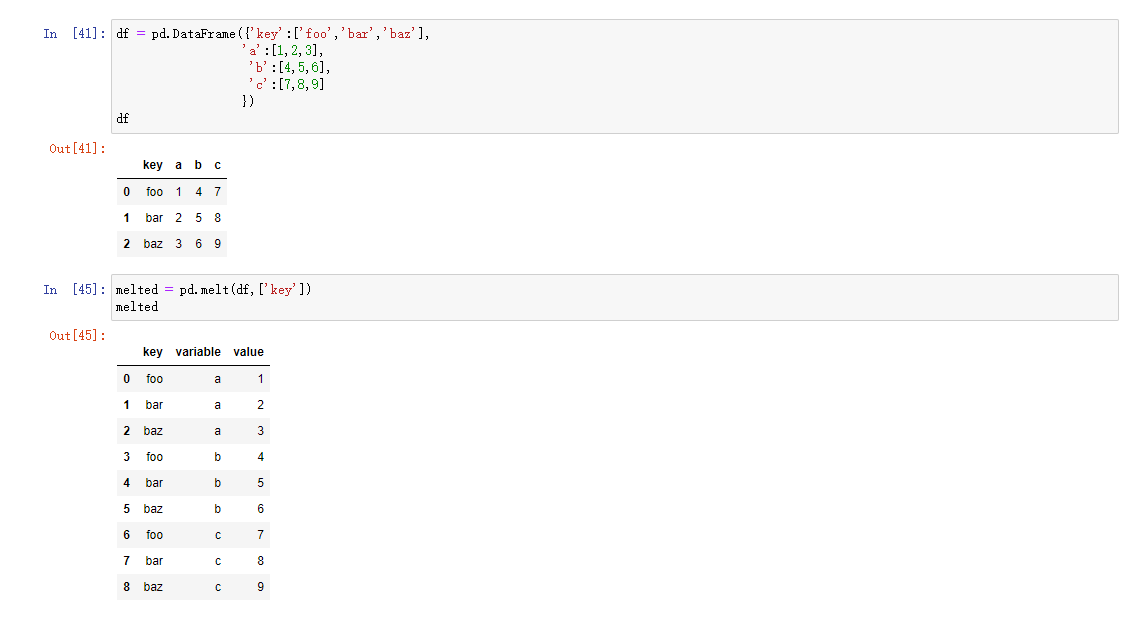
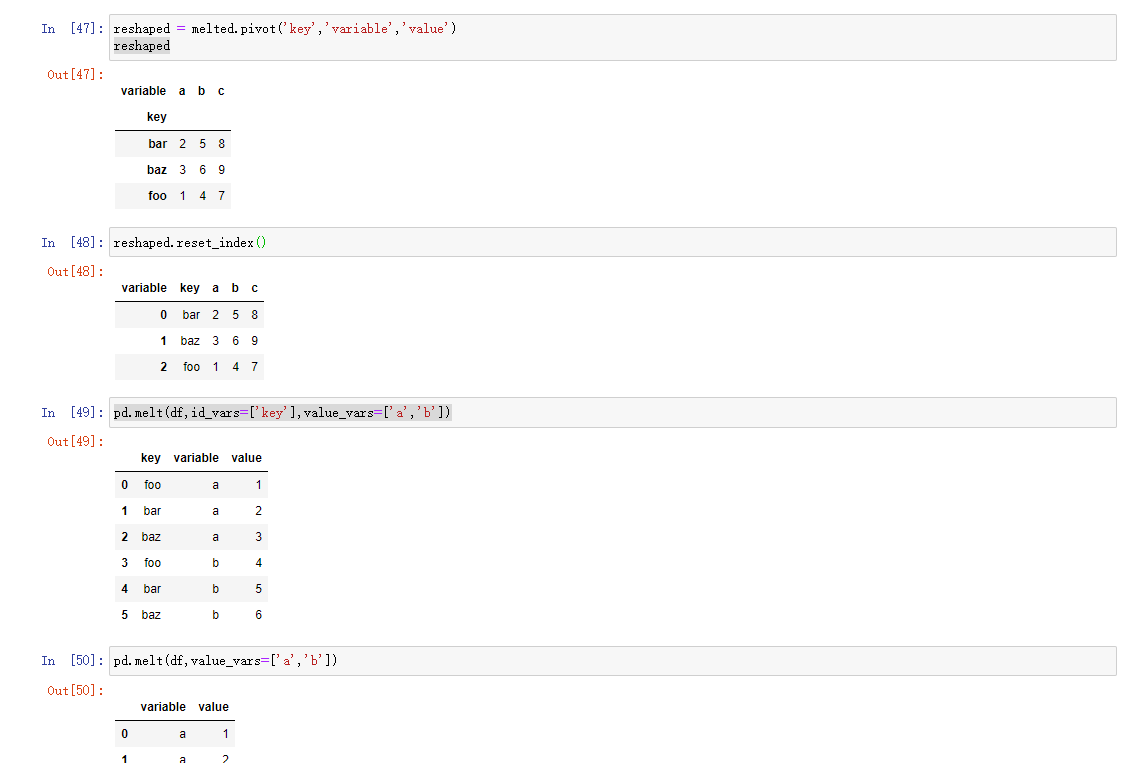
宽变长
pivot方法的反操作是pandas.melt,需要注意的是,需要配置key哪些列是分组指标