数据清洗也是我们的首要准备的,不完美的数据永远都是不完美的
数据清洗与准备1
- 数据分析和建模的过程中,大量的时间都花在了数据准备上
- pandas和内置的python工具提供了一个高级,灵活和快速的工具集
- 着重关注于如何处理缺失值,重复值,字符串操作和其他分析数据转换工具
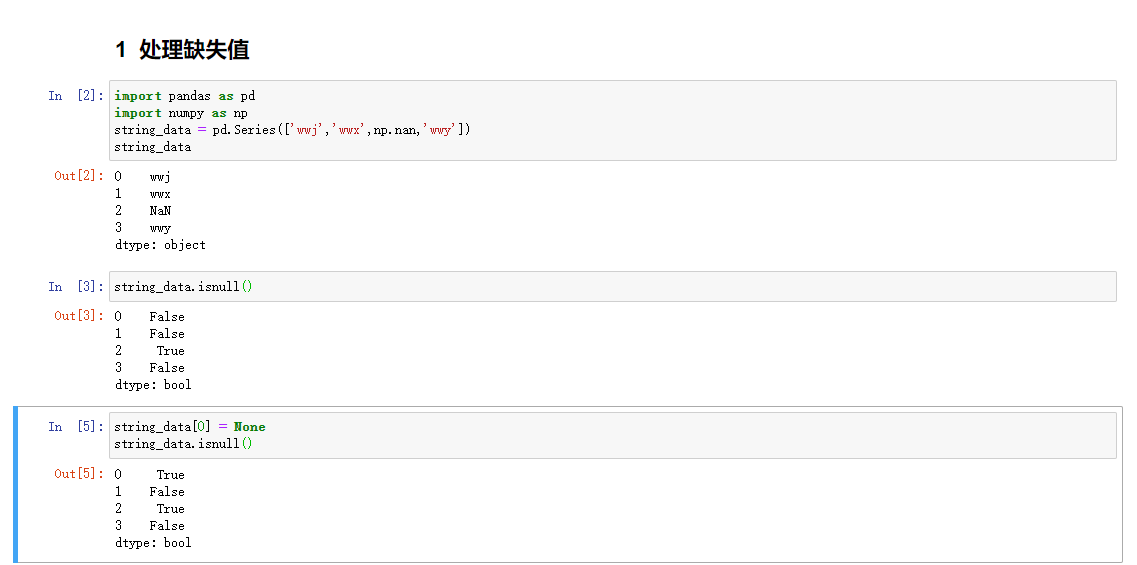
处理缺失值
pandas对象的所有描述性统计信息默认情况下是排除缺失值的
pandas对象中表现缺失值的方式对大部分用户来说还是OK的。对于数值型数据,pandas使用浮点值NaN。一般称作为容易检测到的标识值
- 注意:在统计应用学中,NA数据可以是不存在的数据或者是存在但不可观察的数据
- python内建的None值在对象数组中也被当做NA处理
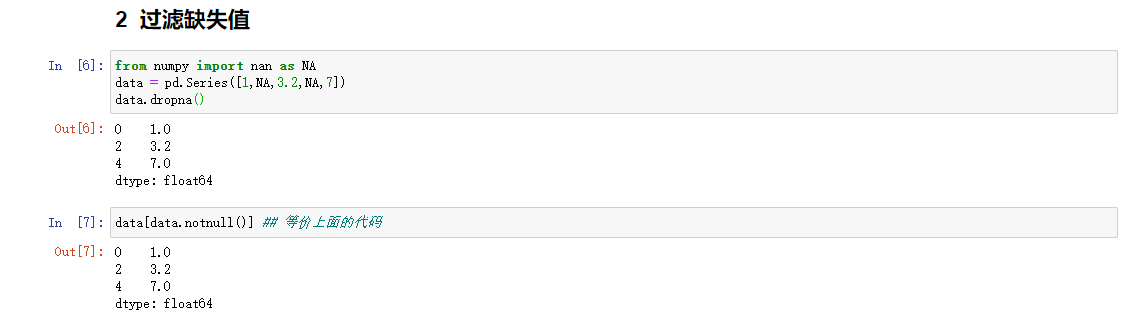
过滤缺失值
使用pandas.isnull和布尔值索引手动的过滤缺失值,但dropna在过滤缺失值非常有用.在Series上使用dropna,它会返回Series中所有的费控数据与其索引值
处理Series
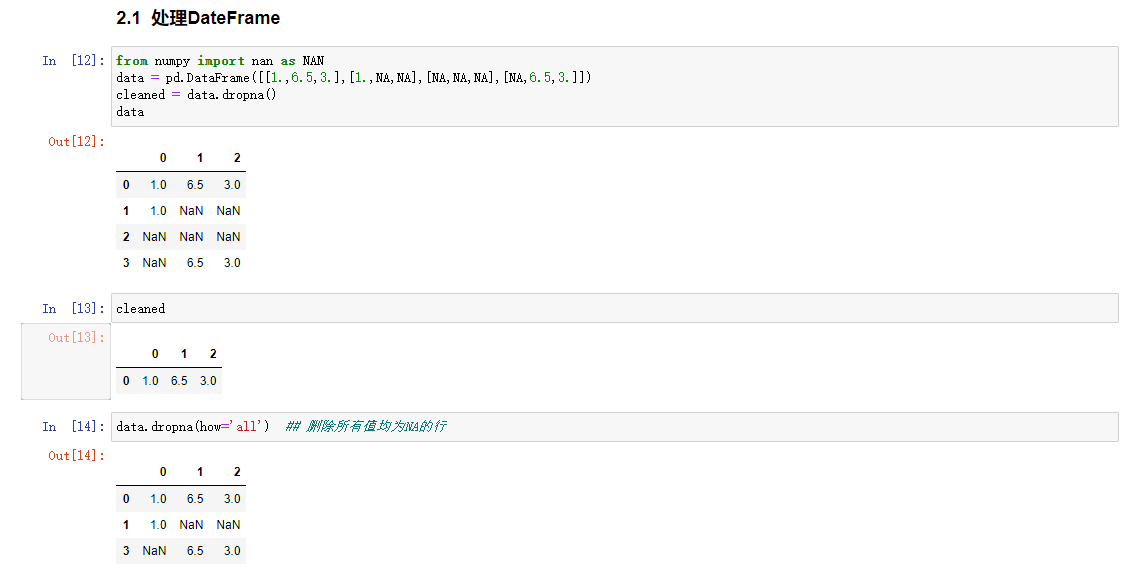
处理DateFrame
处理DataFrame对象时,有可能需要删除全部为NA或者包含有NA的行或者列。dropna默认情况下会删除包含缺失值的行
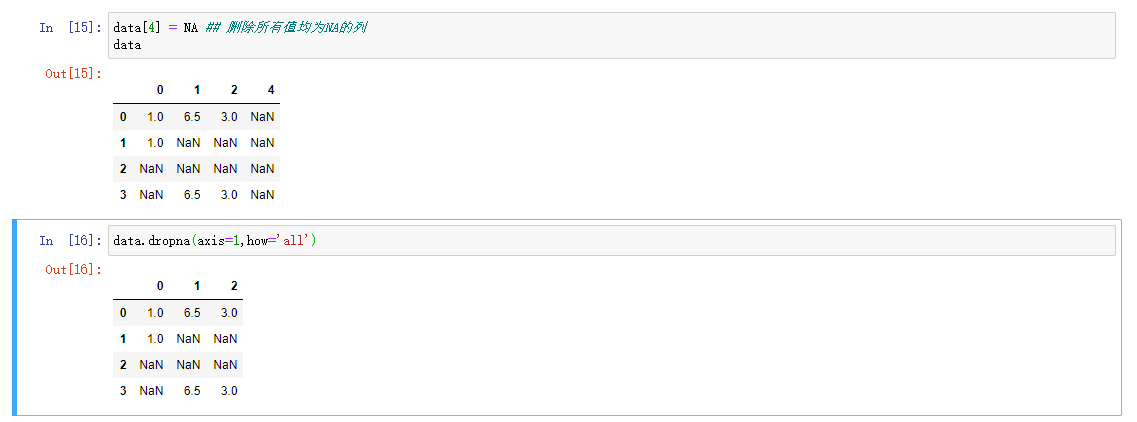
过滤DataFrame的行的相关方法涉及时间序列数据。如果要保留一定数量的观察值的行。可以用thresh参数表示
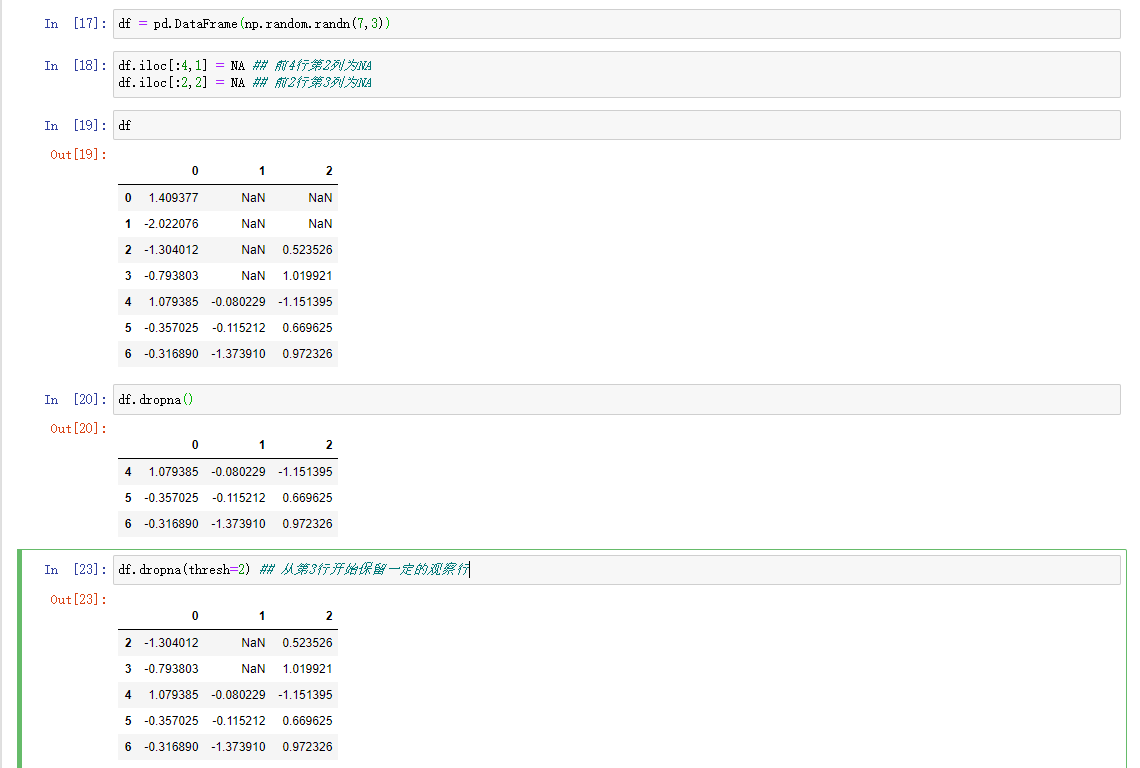
补全缺失值
有时候我们可能需要多种方式补全数据,而不是单纯的过滤缺失值。我们可以使用fillna的方法补全缺失值,调用该方法时可以使用一个常数替代缺失值
fillna的基本操作
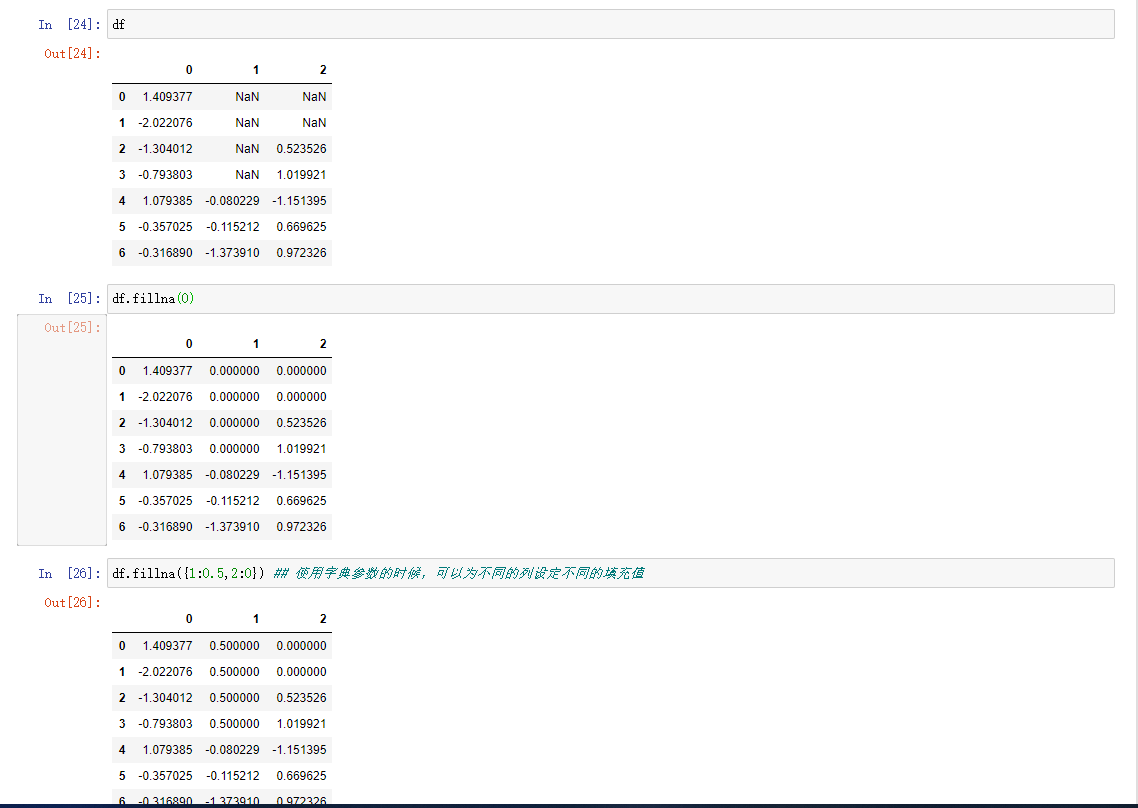
额外操作


Series填充(mean()平均值 median()中位数 max()最大值 min()最小值 sum()求和 std()标准差)

数据转换
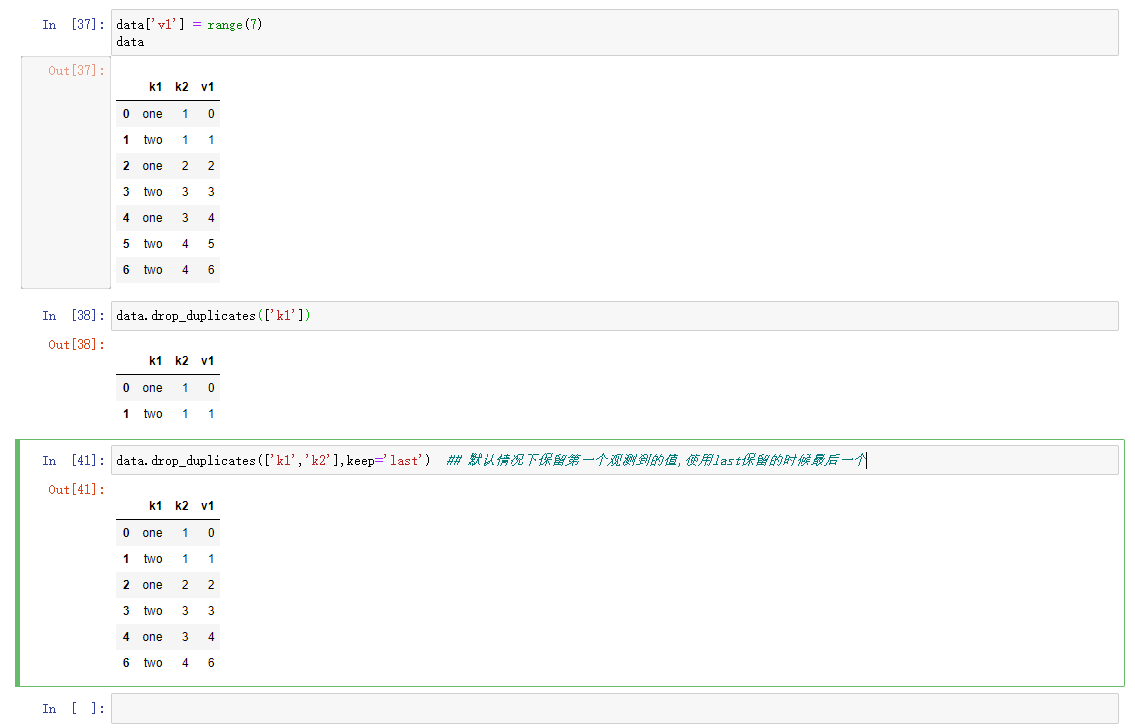
删除重复值
由于各种原因,DataFrame中会出现重复的行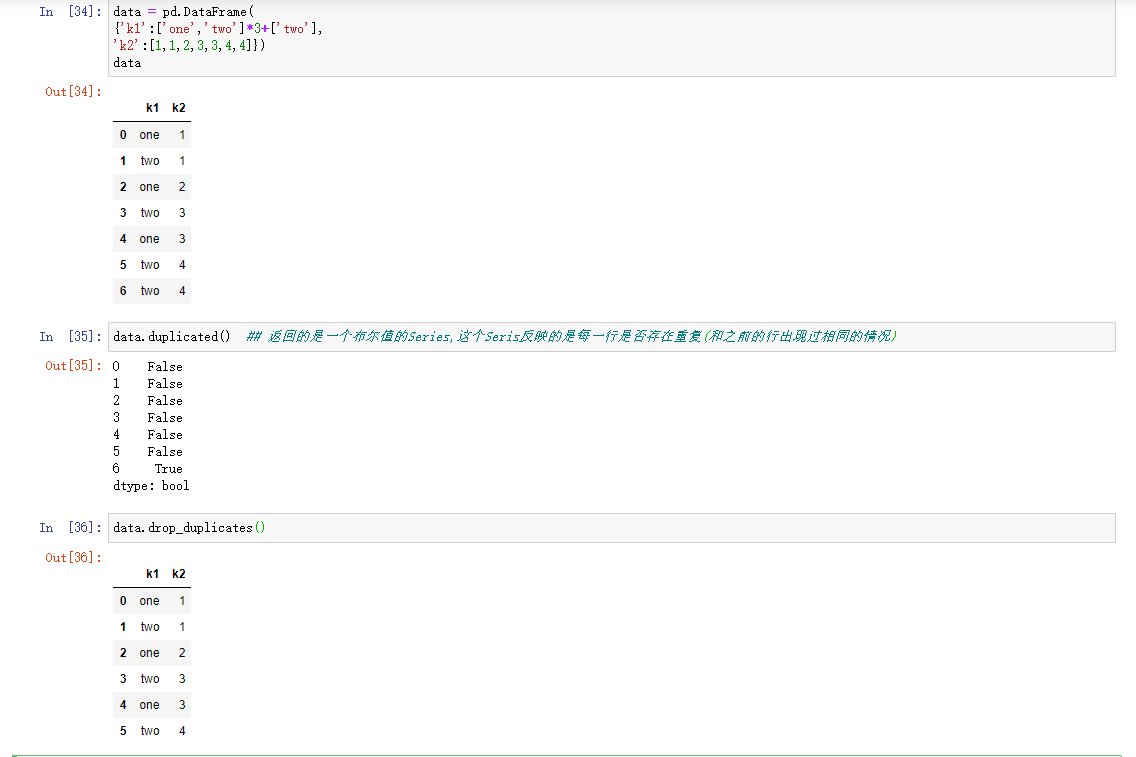
默认方法都是按照对列进行操作。可以指定数据的任何子集检测是否有重复
使用函数或映射进行数据转换
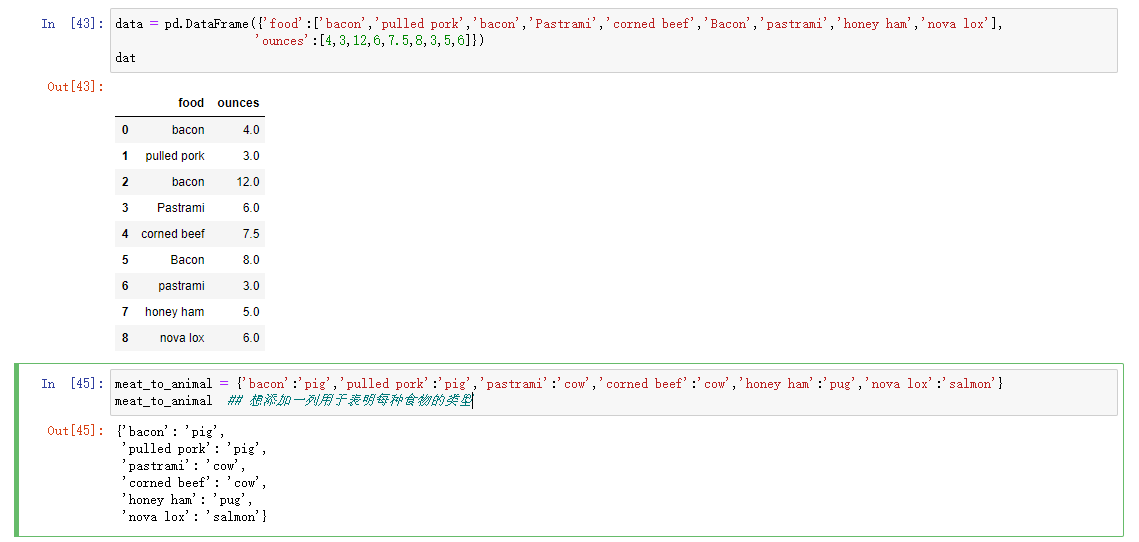
Series的map方法接受一个函数或者一个包含映射关系的字典型对象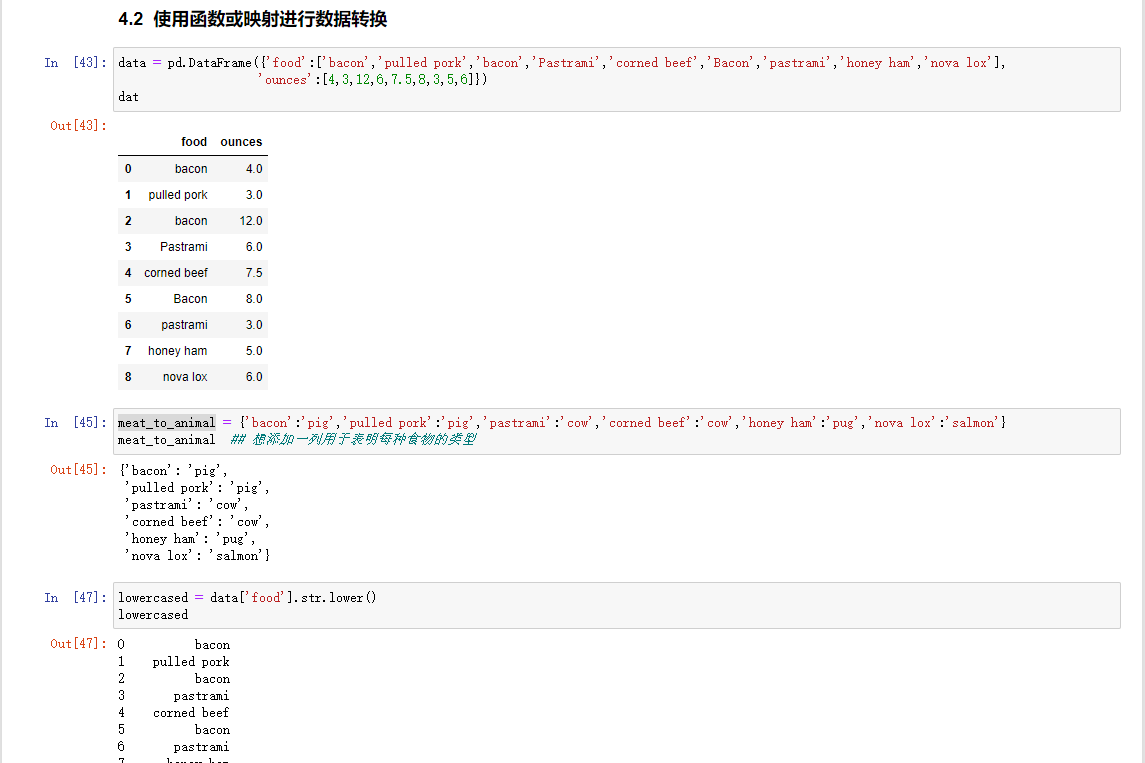
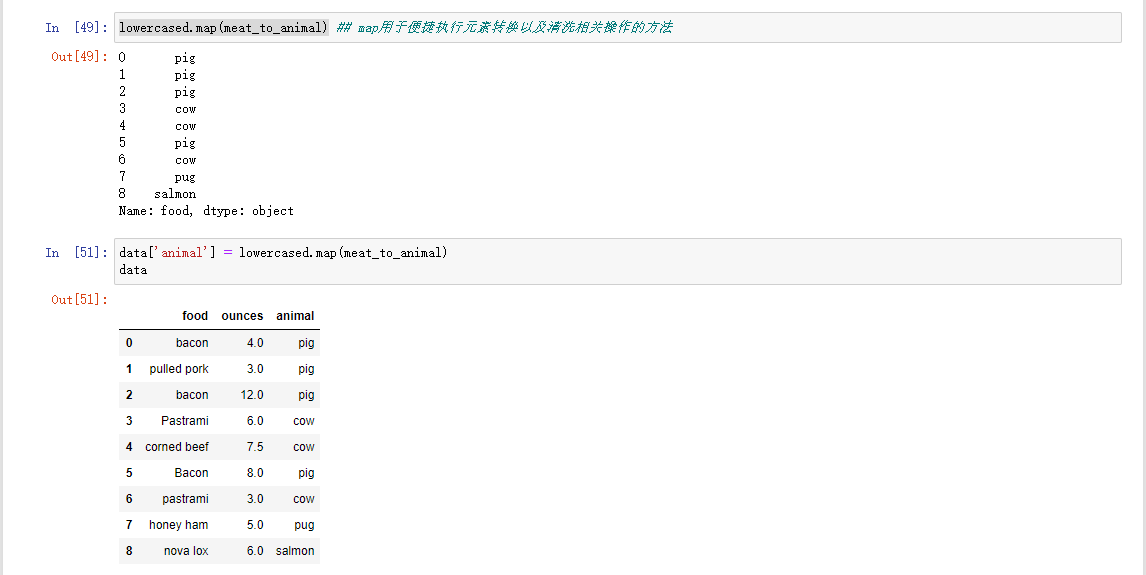
函数级操作
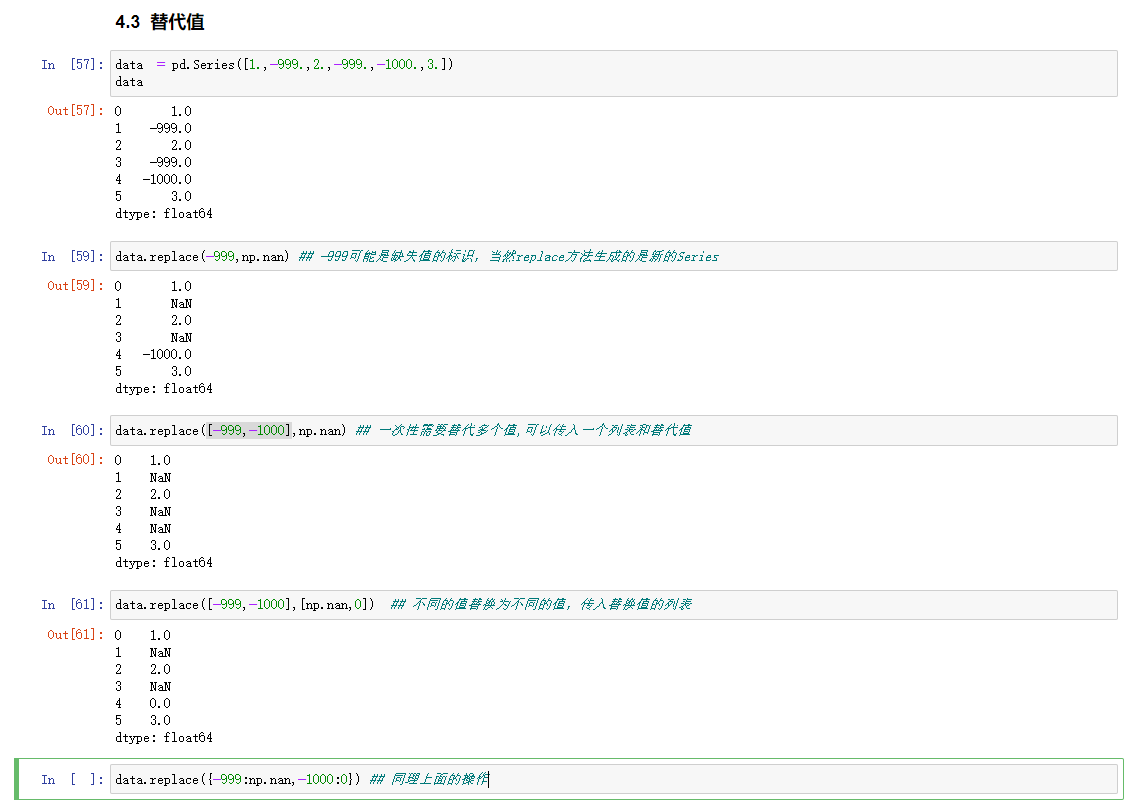
替代值
使用fillna填充缺失值,map可以用来修改一个对象中的子集的值。但是replace提供了更为简单的灵活的实现。对于Series使用map,对于DataFrame来说使用apply或者applymap
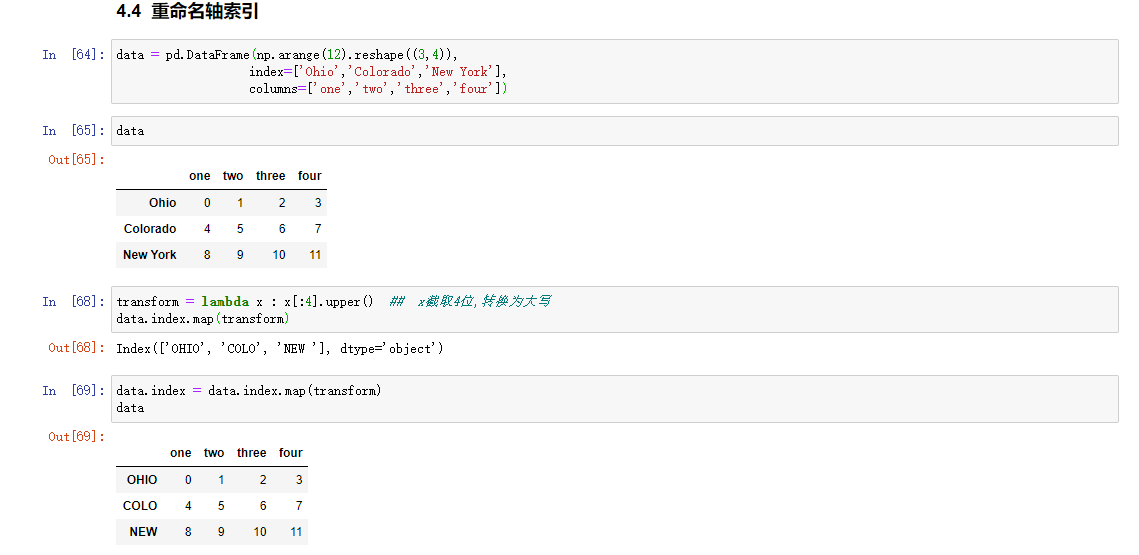
重命名轴索引
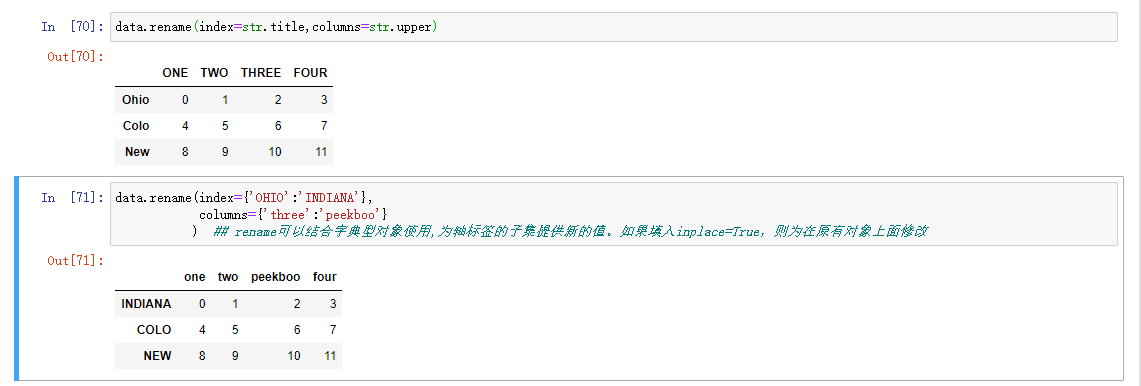
创建数据集转换后的版本,使用rename
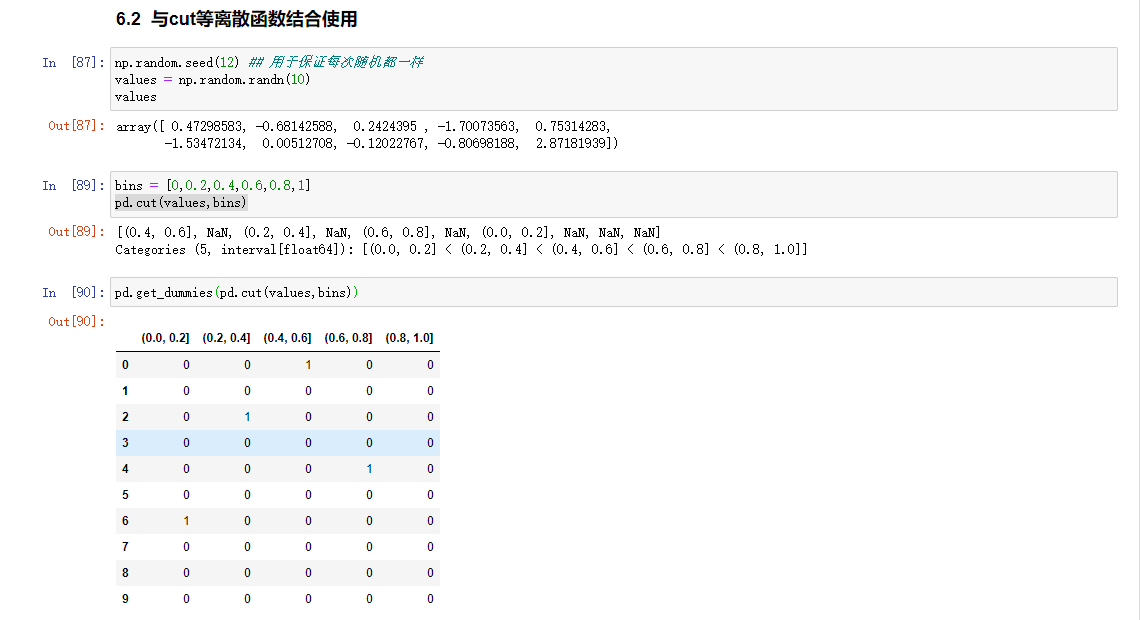
离散化和分箱
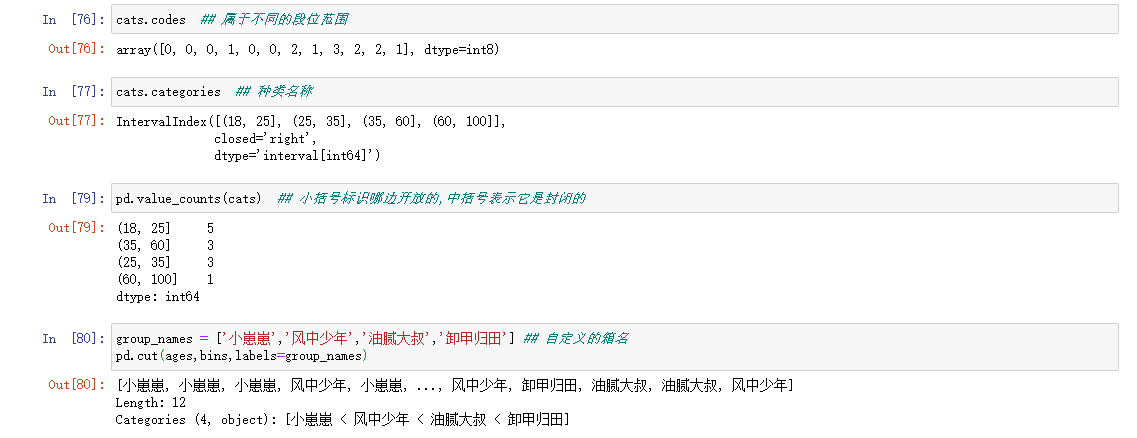
连续值经常需要离散化或者分离成‘箱子’进行分析。
现架设某项研究中一组人群的数据,你想将他们分组,放入离散的年龄框中

注意:pandas返回的对象是一个特殊的categorical对象,输出了描述由pandas.cut计算出的箱。里面指定了不同类别的名称以及codes属性中的ages
进阶操作
pandas一般根据数据中的最大值和最小值计算出等长的箱

使用qcut可以定义等长的箱以及自定义分位数

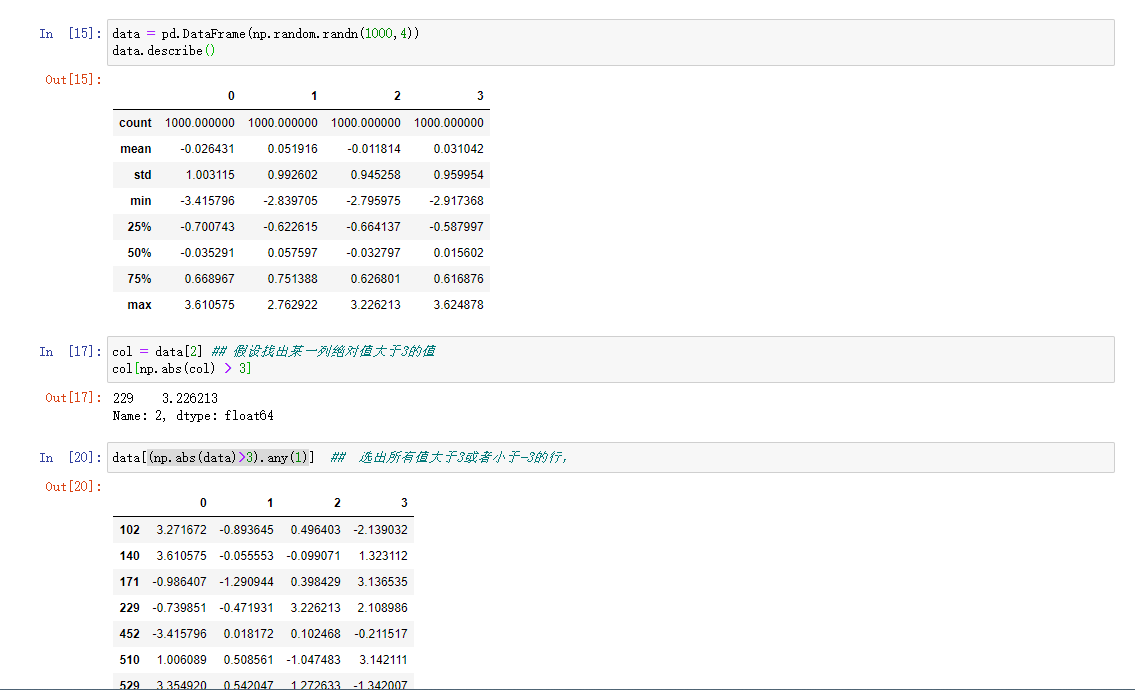
检测和过滤异常值
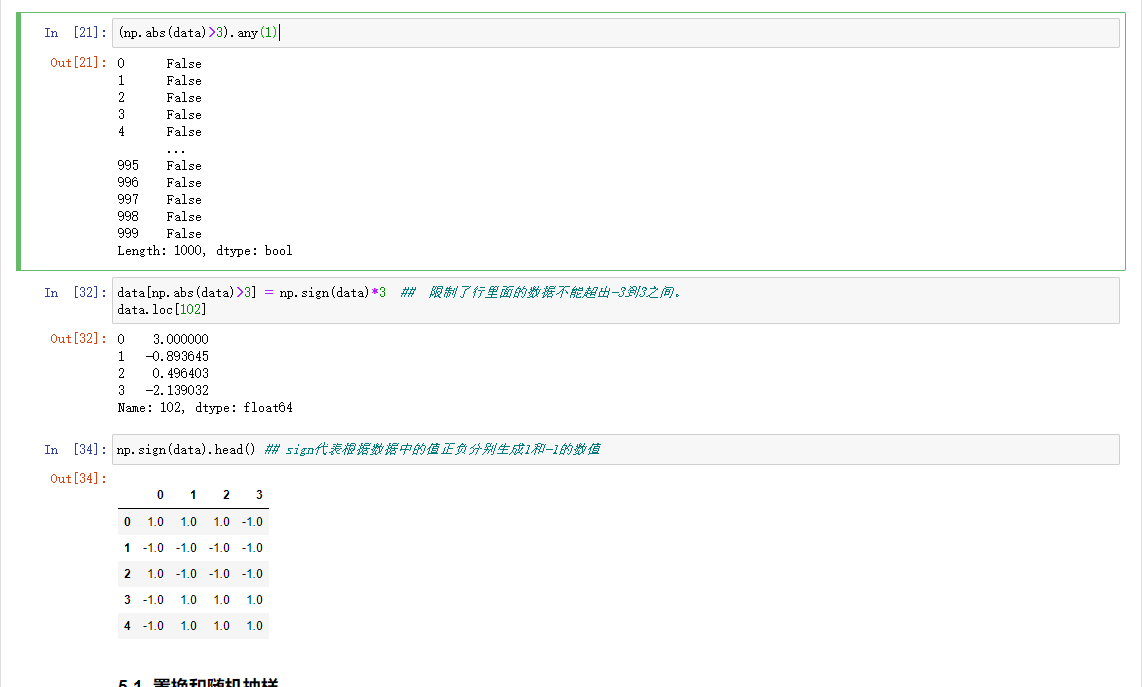
过滤和转换异常值一般是应用数组。比如
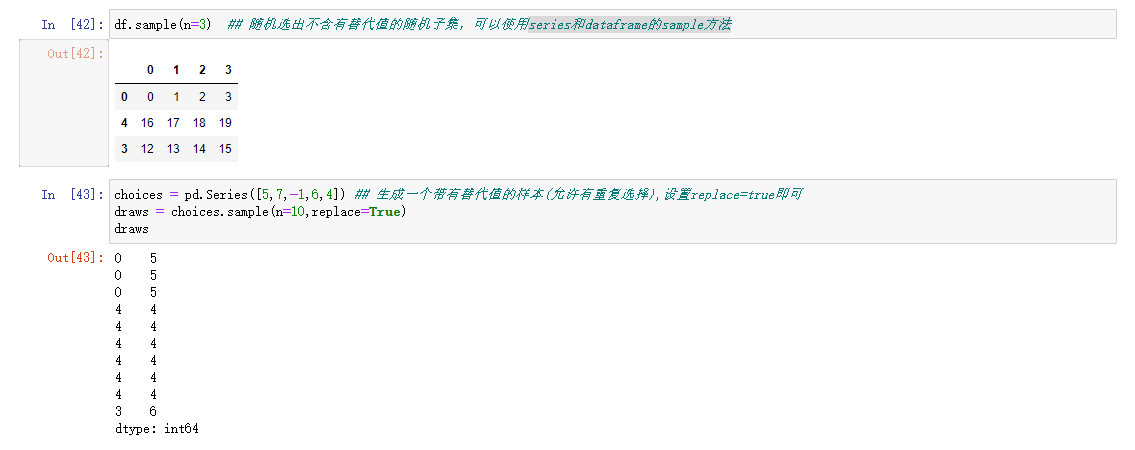
置换和随机抽样
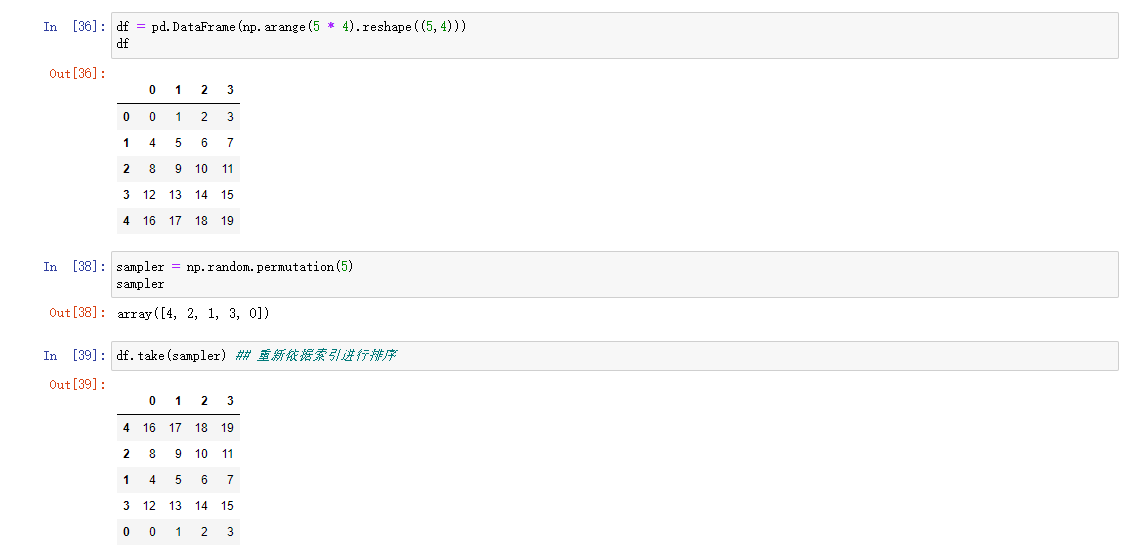
使用np.random中的permutation可以对DataFrame中的Series或行进行置换(随机排序),调用该操作可以根据需要的轴长度产生一个表示新顺序的整数数组
计算指标/虚拟变量
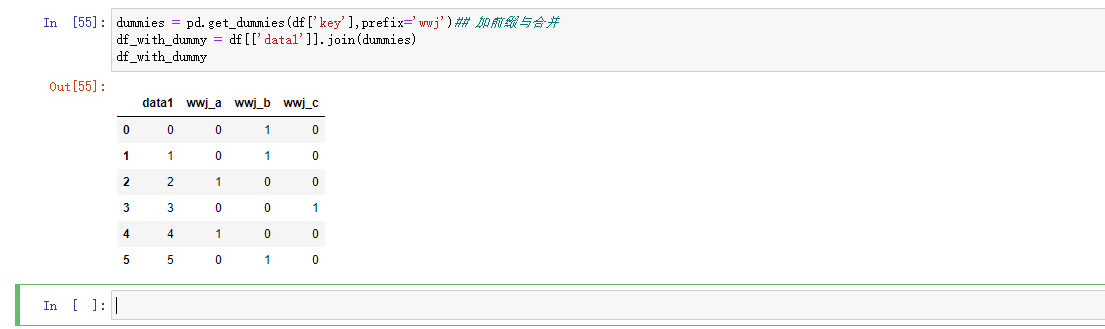
将分类变量转换为虚拟或者指标矩阵是另一种转换操作,如果DataFrame中的一列有K个不同的值,则可以衍生一个K列的值为1和0的矩阵或DataFrame,在pandas中有一个get_dummies函数可以实现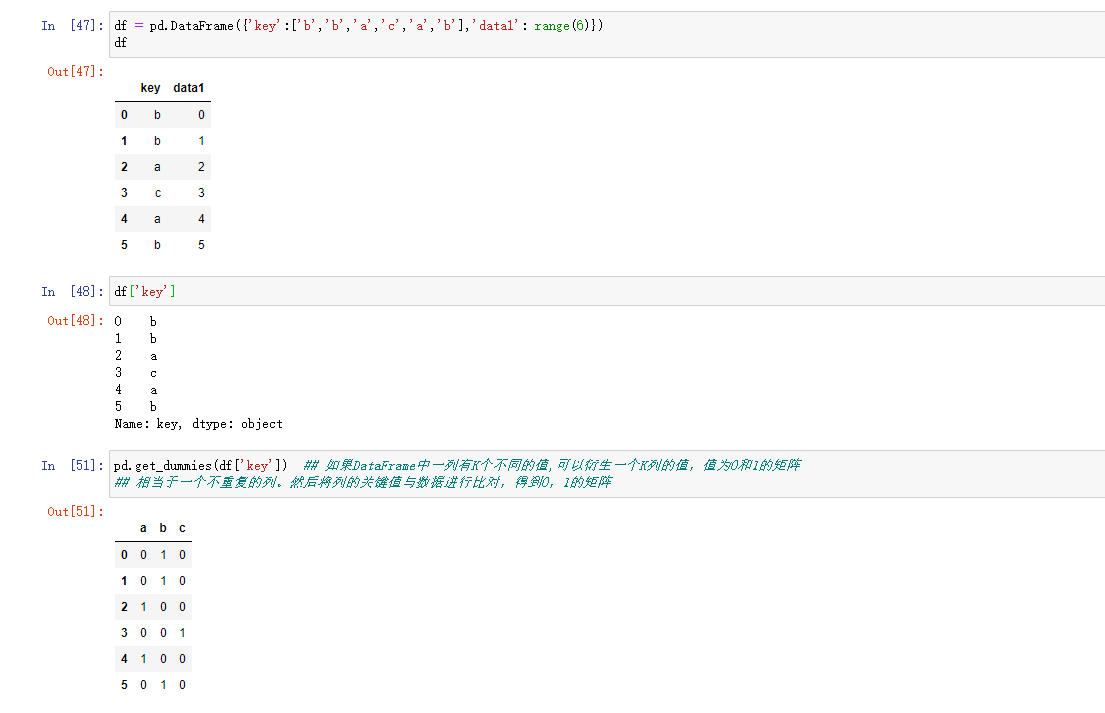
处理一行属于多类别的数据
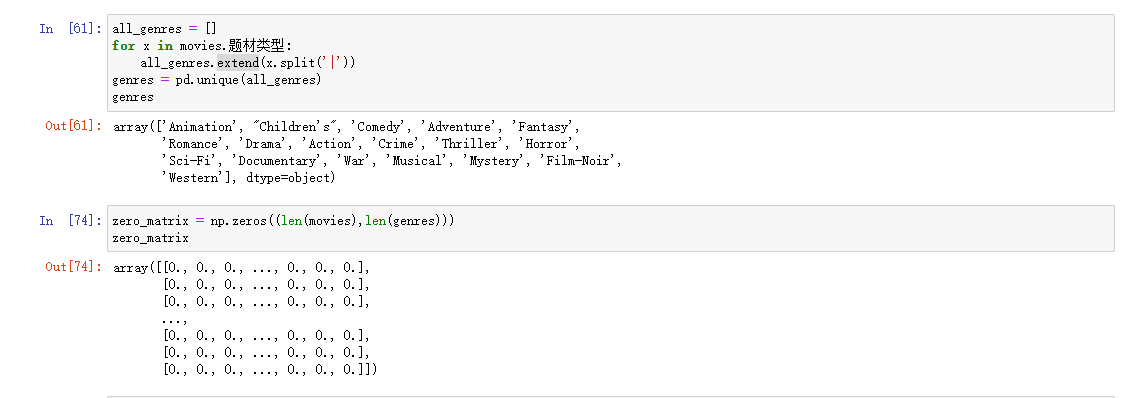
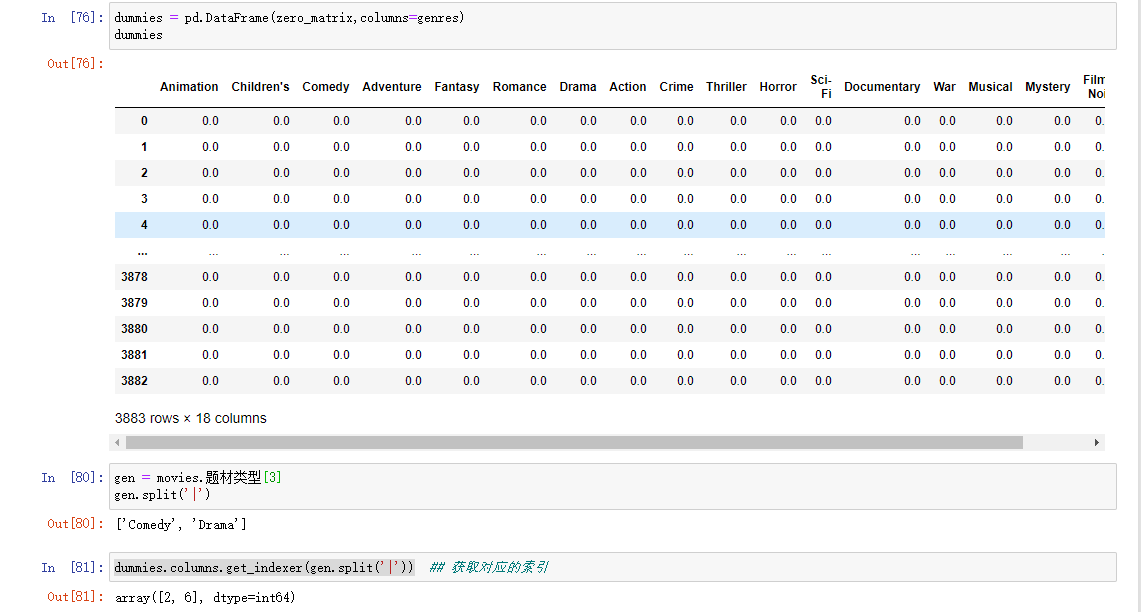
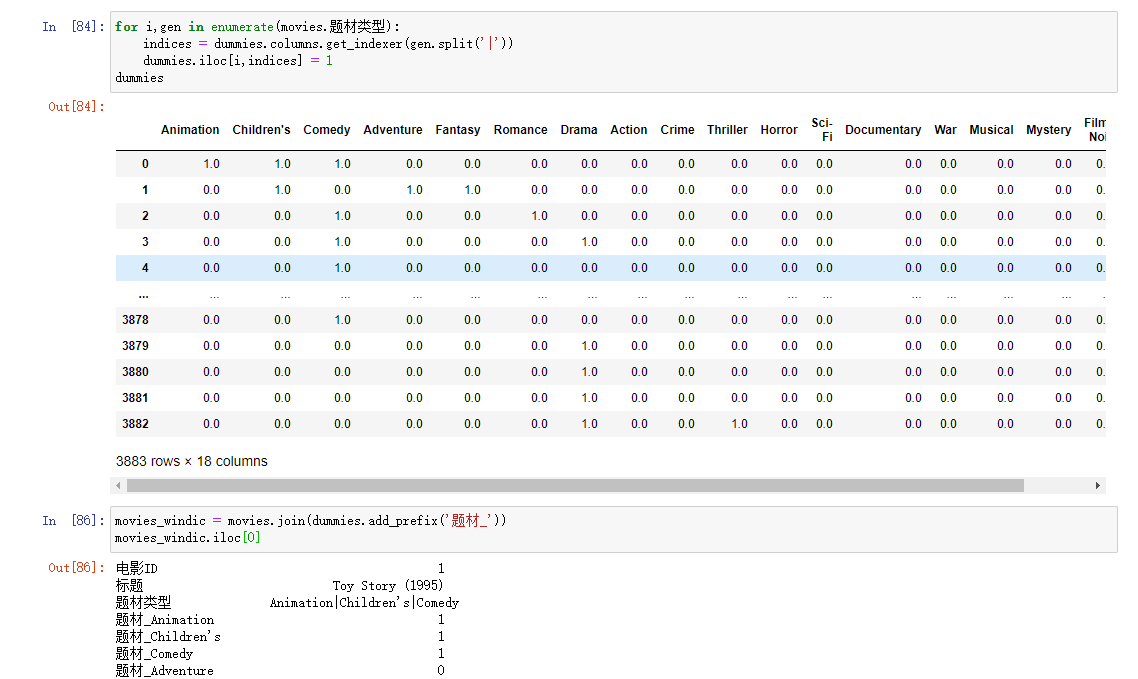
与cut等离散化函数结合使用