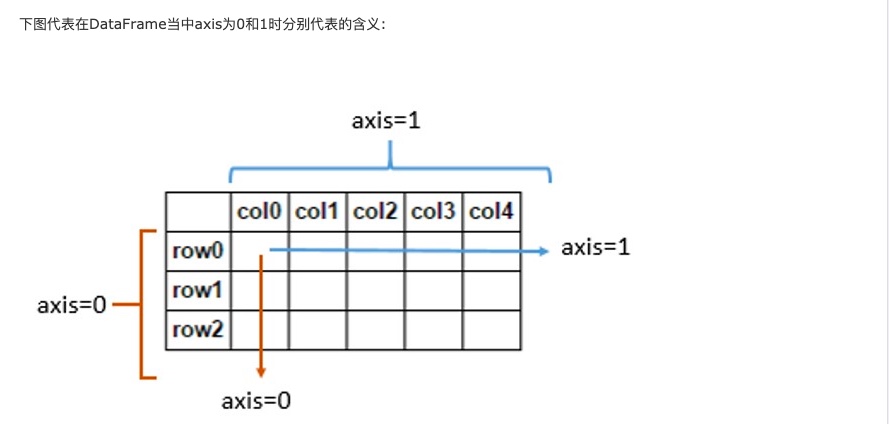
pandas基础二
- 基本功能
基本功能
介绍Series和DataFrame的数据的基本操作
重新索引
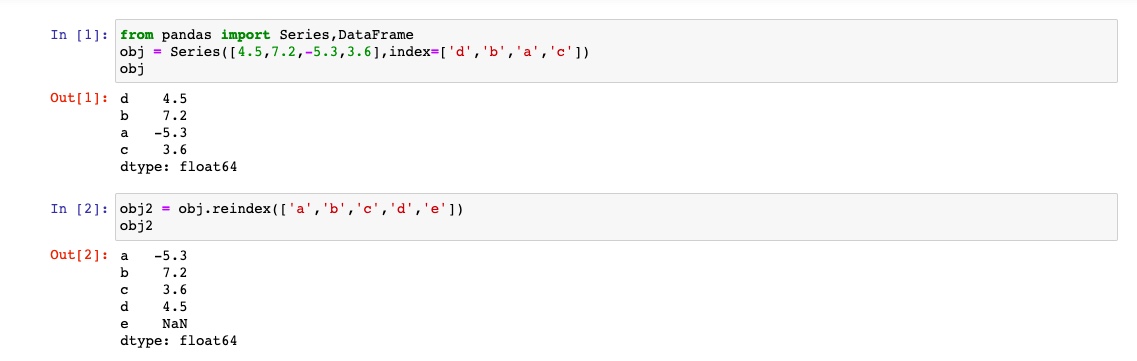
pandas对象的一个重要方法是reindex,其作用是创建一个新对象,它的数据符合新的索引
索引会根据reindex进行重排.如果某个索引值不存在,引入缺失值
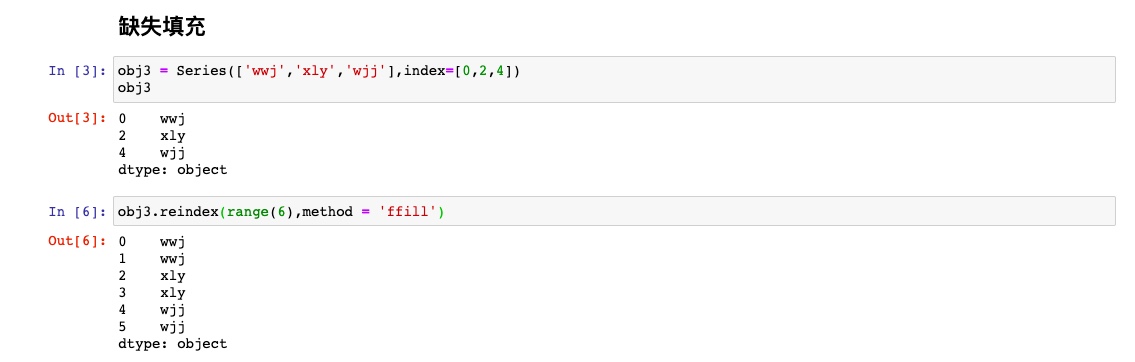
对于时间序列的有序数据,重新索引需要一些插值处理.method选项可以操作,ffill是使用前面的值填充,bfill是使用后面的值填充。
如果使用dataFrame,reindex可以修改行索引和列.只传递一个序列时,会重新索引结果的行
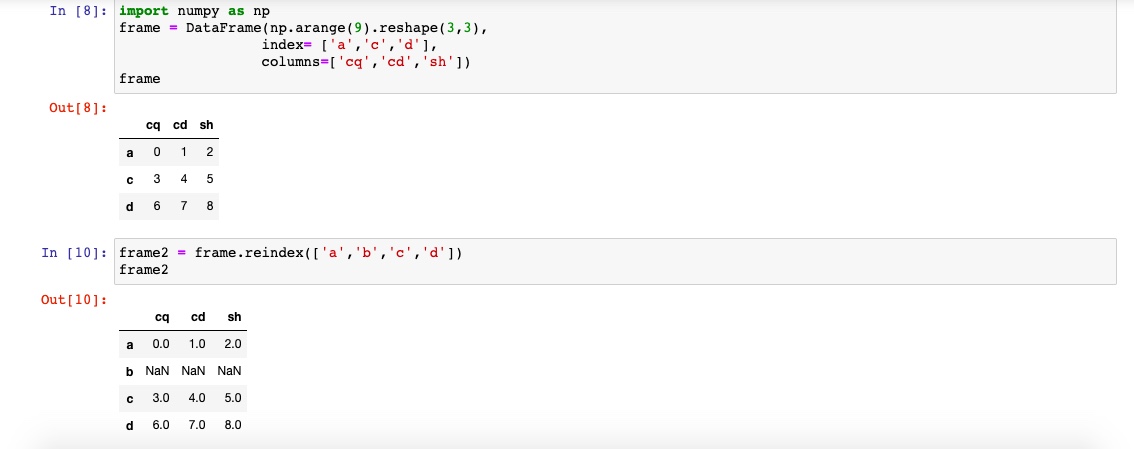
同样的可以用column重新索引

丢弃指定轴上的项
丢弃某条轴上面的一个或多个项很简单,只要有一个索引数组和列表即可
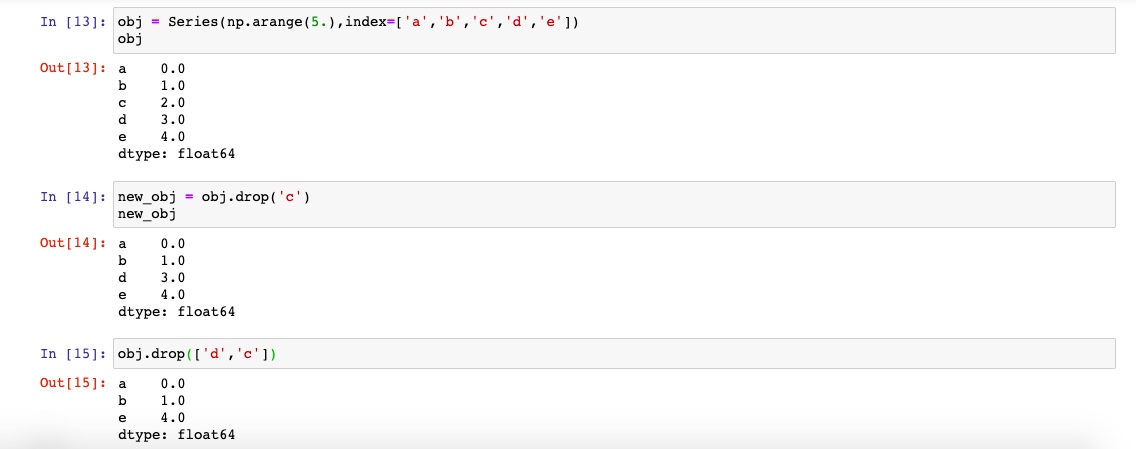
针对series
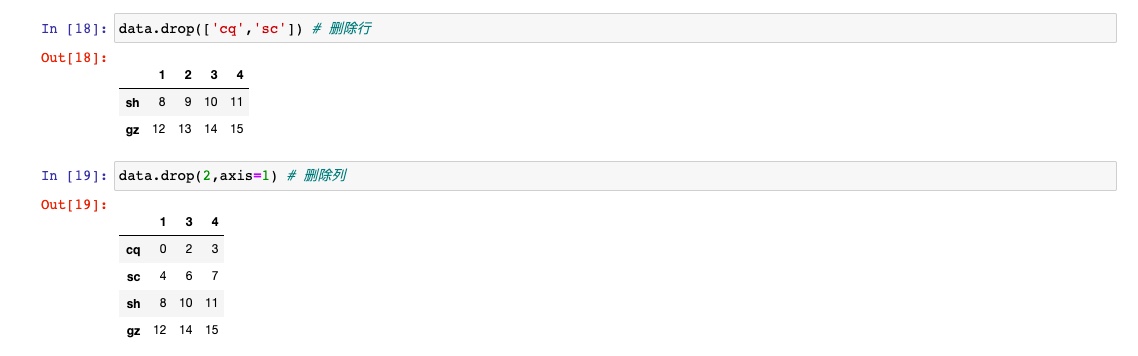
针对DataFrame
索引,选取和过滤
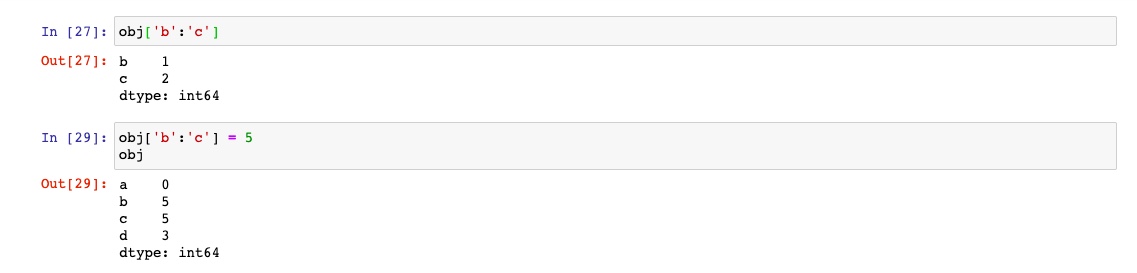
Series索引的工作方式类似numpy的索引,不过Series索引不只是整数
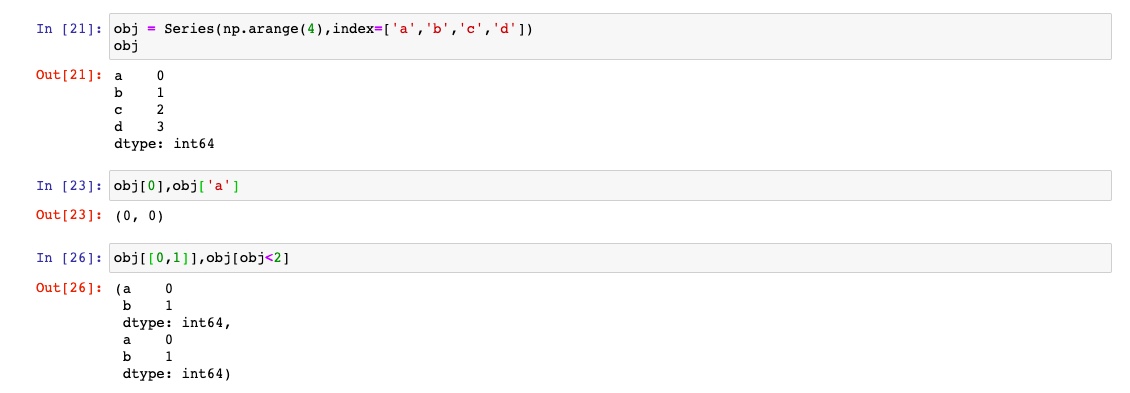
切片运算有一些不同,其尾部是包含的
针对DataFrame进行索引就是获取一个或者多个列
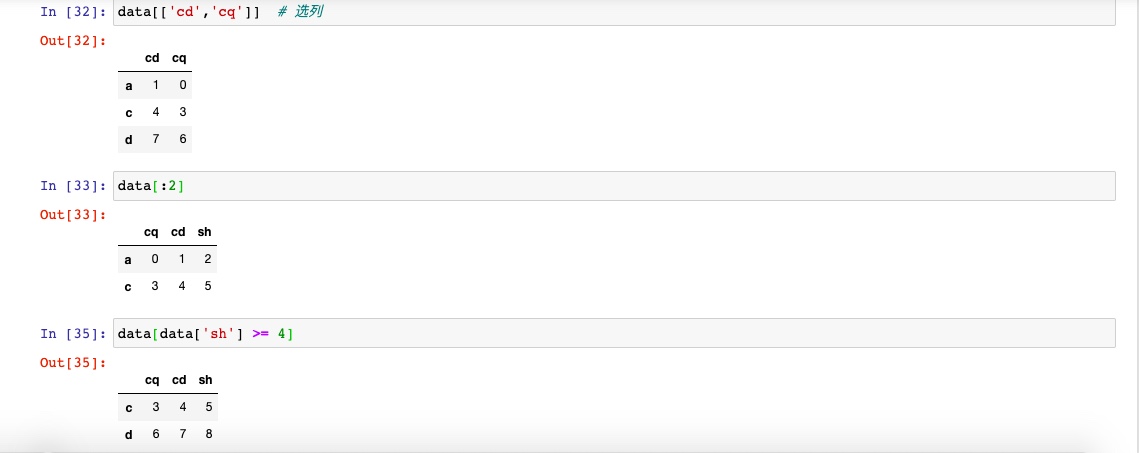
通过布尔类型
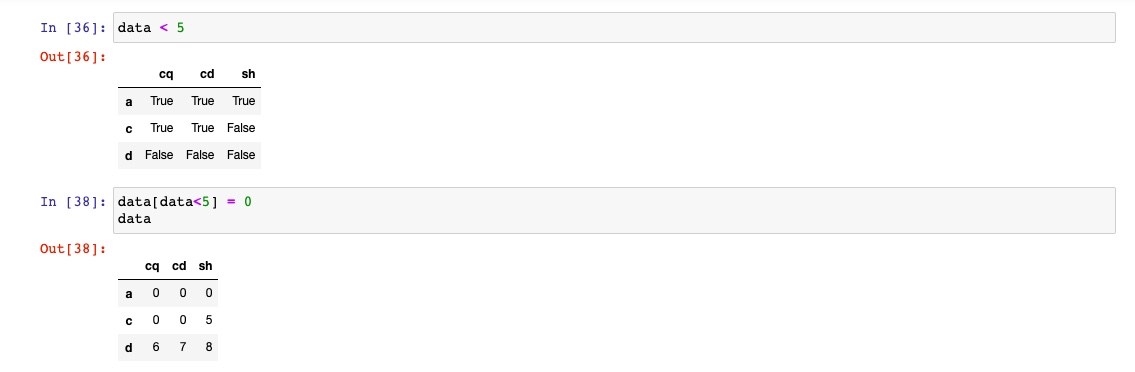
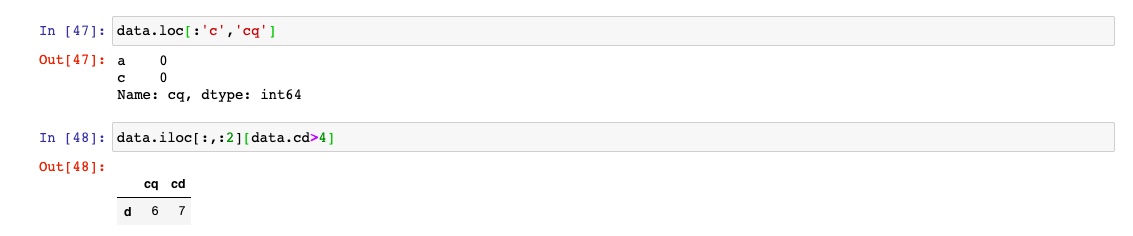
用loc和iloc进行选取
对于dataFrame的行的标签索引可以使用loc和iloc,从DataFrame选择行和列的子集
通过2个方法选择一行和多列
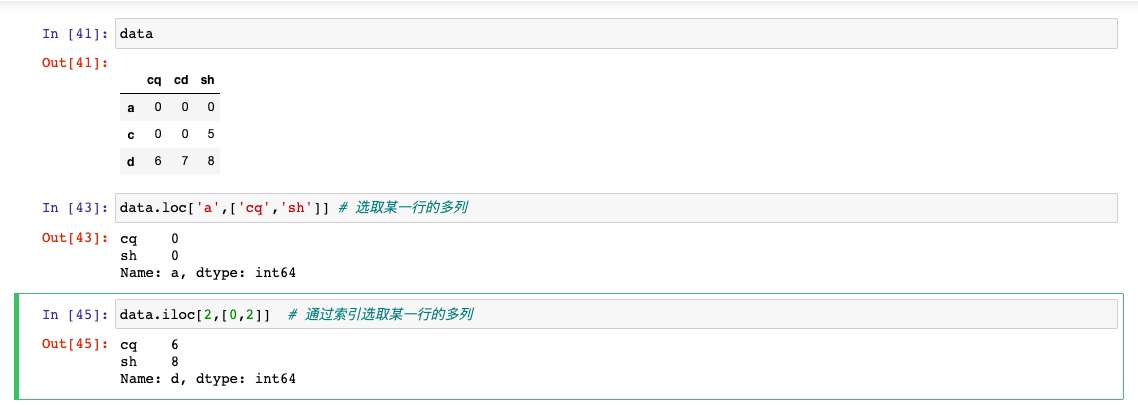
同样适用于一个标签或者多个标签的切片
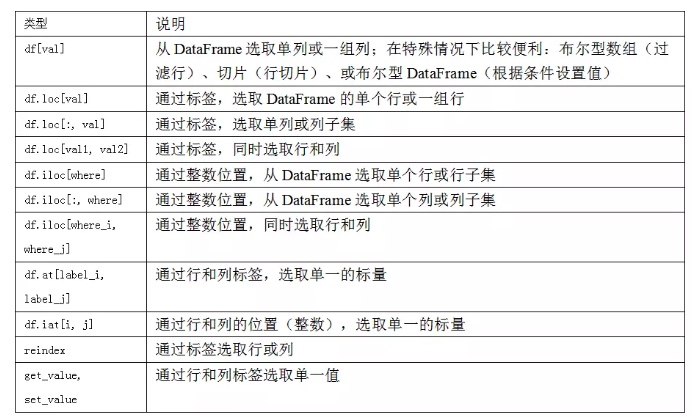
一些方法
算术预算和数据对齐
pandas重要的功能可以对不同索引的对象进行算术运算.对象相加时,存在不同的索引对.结果的索引就是该索引对的并集.

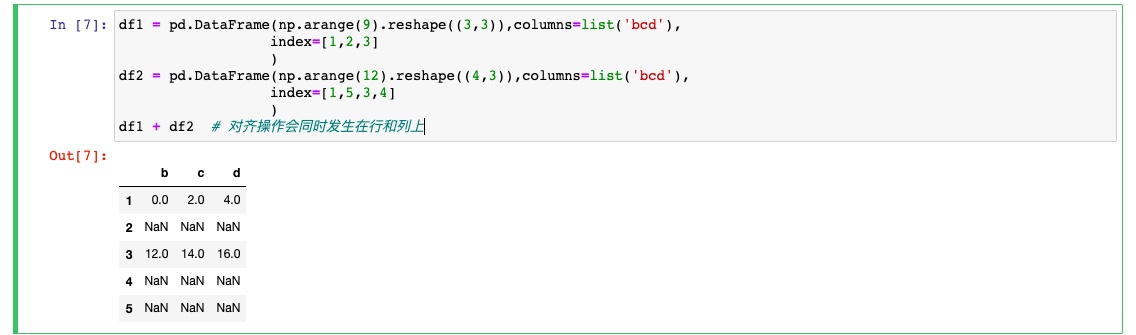
注意:Dataframe相加,没有共用的列或者行标签.结果都会是空
在算术方法中填充值
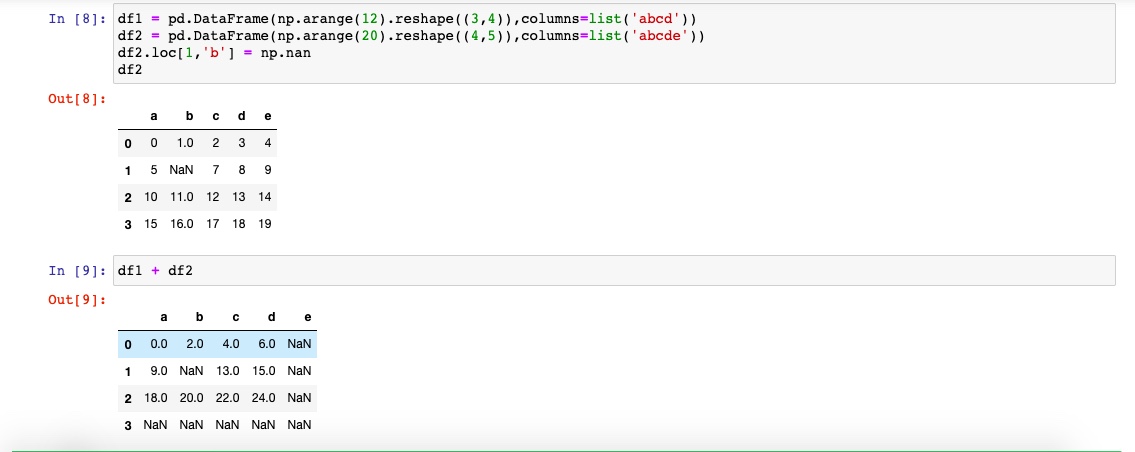
现在出现了na值,我填充一个特殊值怎么做

可用的方法
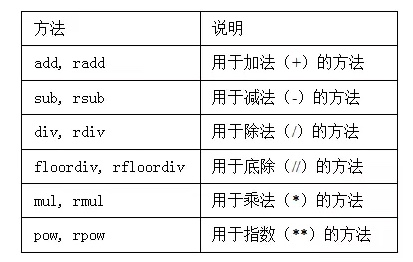
同理

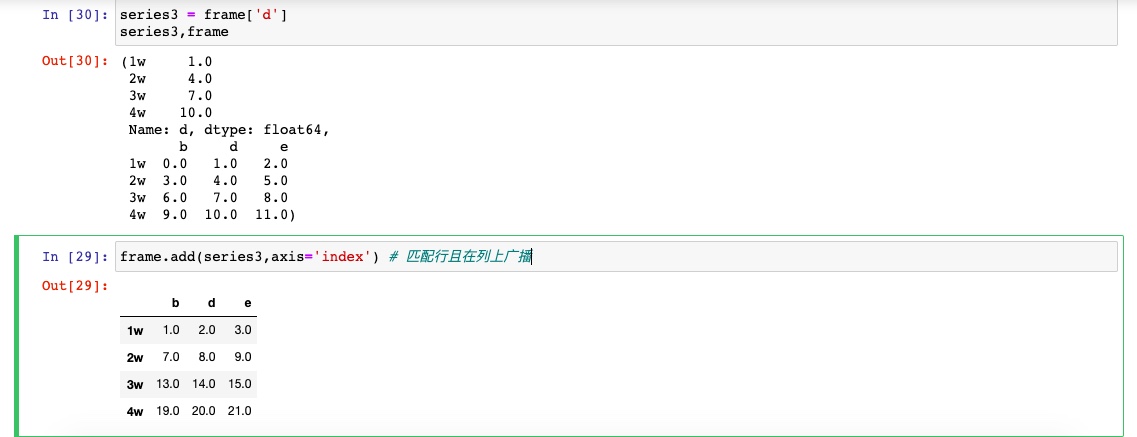
DataFrame和Series之间的运算
先看一个二维数组和一维数组相加
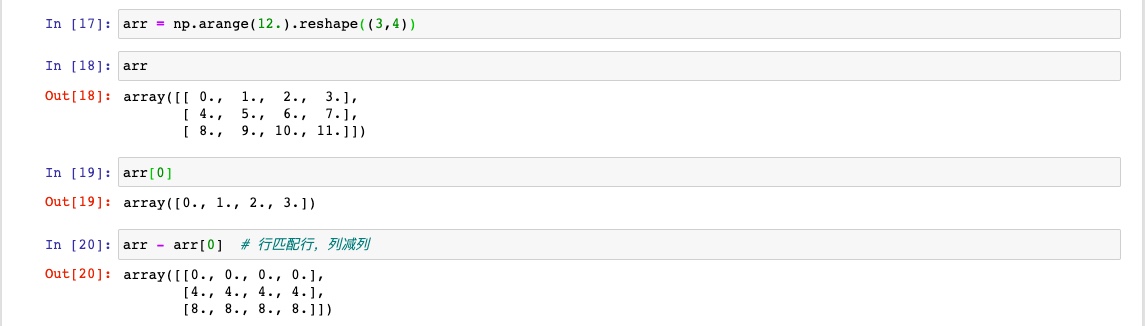
同理,2者相加也一样
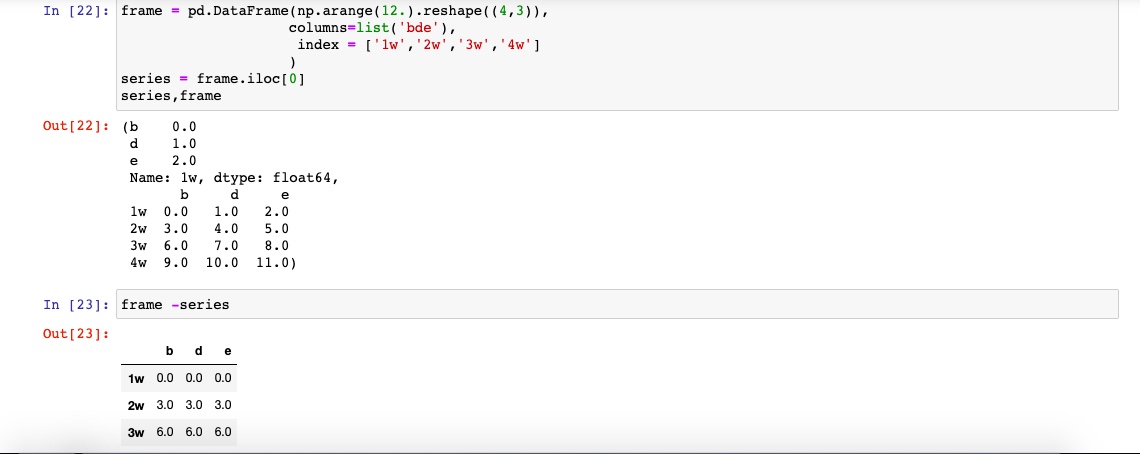
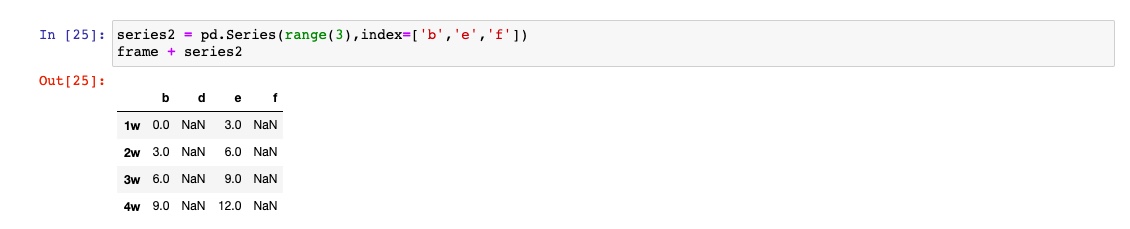
如果某个索引值找不到,则形成并集
函数应用和映射
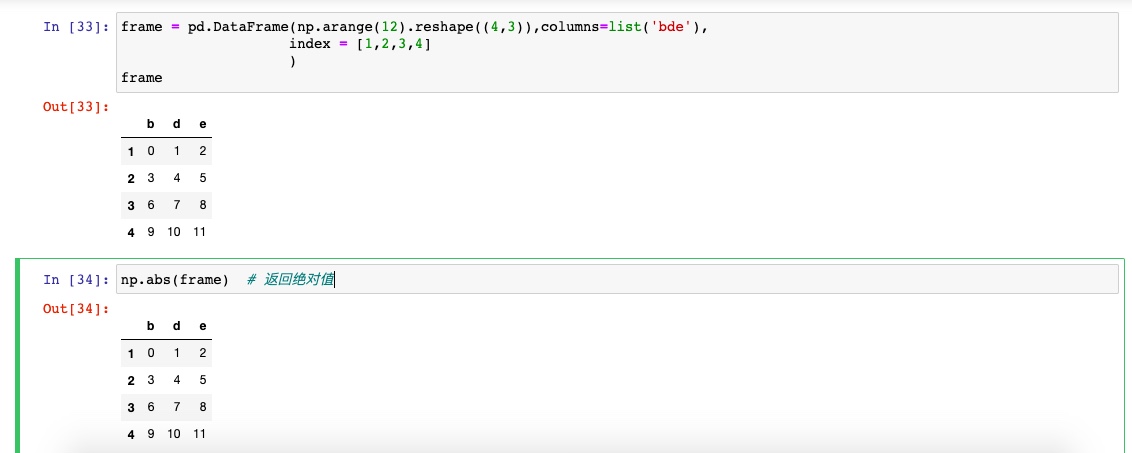
Numpy的ufuncs也可以用于操作pandas对象
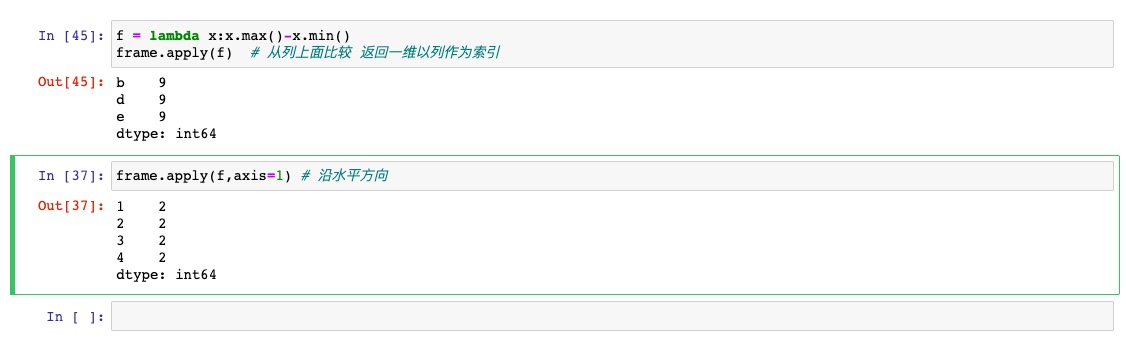
排序和排名
根据条件对数据集进行排序也是一种重要的内置计算,对行和列索引进行排序可以使用sortindex,返回一个已排序的新对象

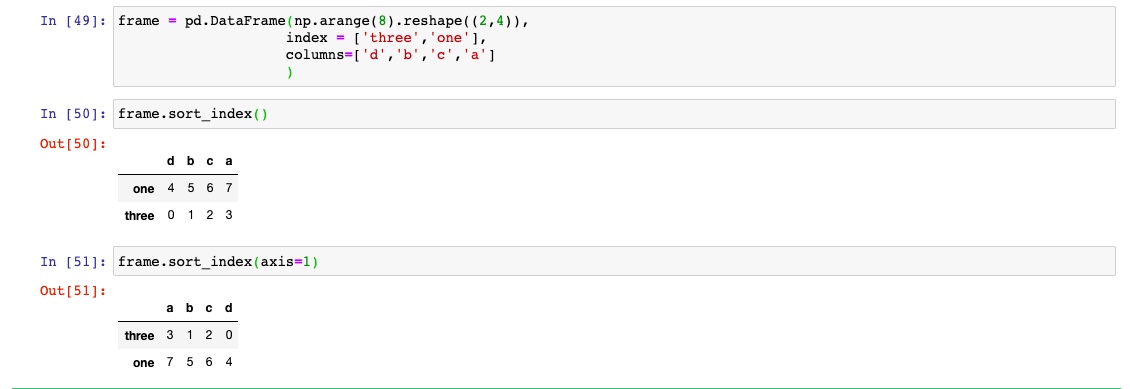
升序或者降序

按值对series排列使用sortvalues

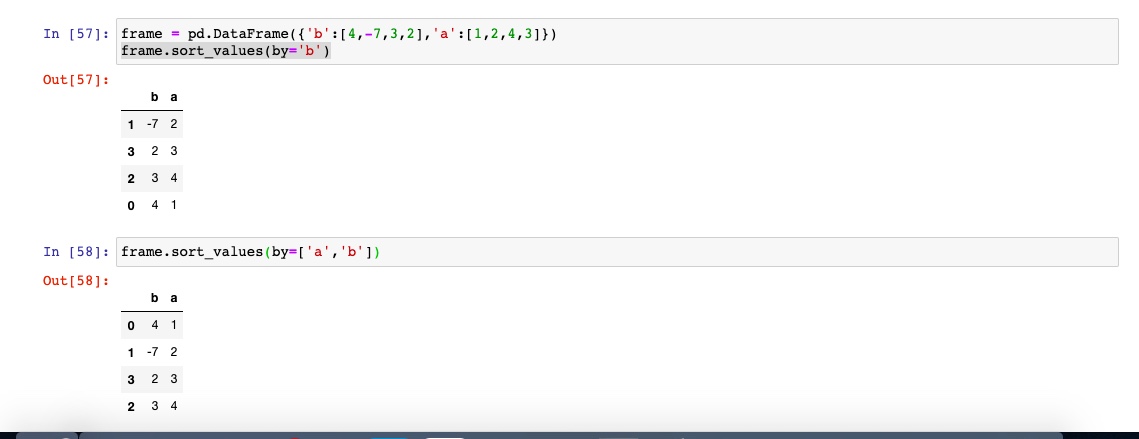
排序DataFrame时,可以根据一个或者多个列中的值,使用sorvalues中的by即可
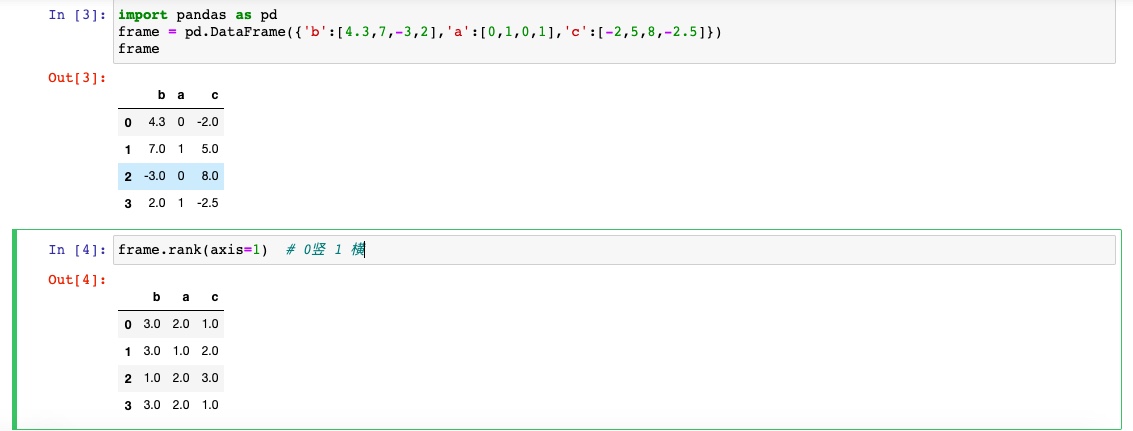
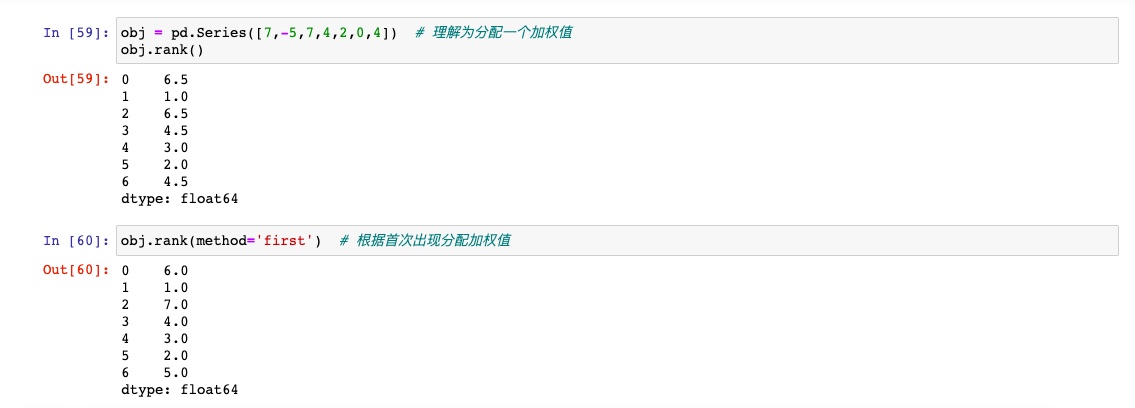
rank方法
rank是通过为各组分配一个平均排名的方式破坏平级关系
针对dataframe