数据分析之路漫漫,贵在坚持.梅花香自苦寒来
pandas基础一
- pandas的数据结构说明
- pandas的数据结构介绍
pandas的数据结构说明
pandas含有使数据清洗和分析工作变得更快更简单的数据结构和操作工具
pandas是基于Numpy数组构建的,特别是基于数组的函数和不适用for循环的数据处理
特点
- pandas是专门为处理表格和混杂数据设计的
- 而Numpy更适合处理统一的数值数组数据
- 用的最多的是使用Series 和 DataFrame
注意:别忘记安装pandas库

pandas数据结构介绍
pandas主要有2个非常重要的数据结构,分别是Series和DataFrame,他们提供了一种可靠的易于使用的基础
Series
Series类似于一维数组的对象,由一组数据以及一组与之相关的数据标签组成
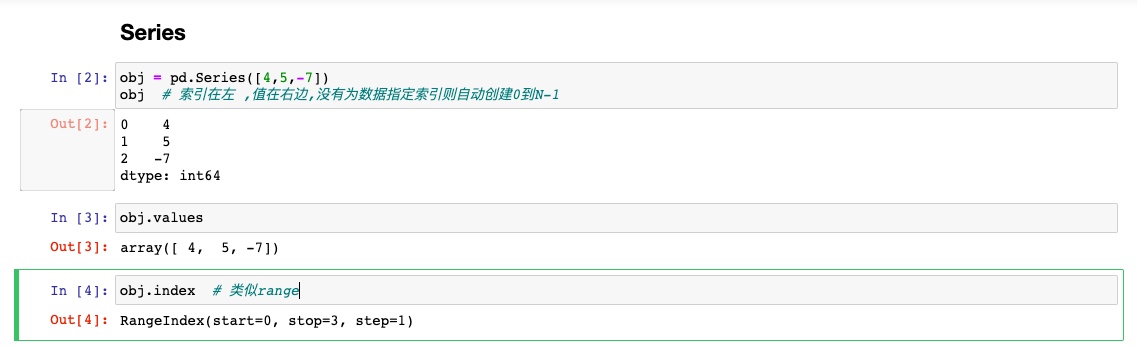
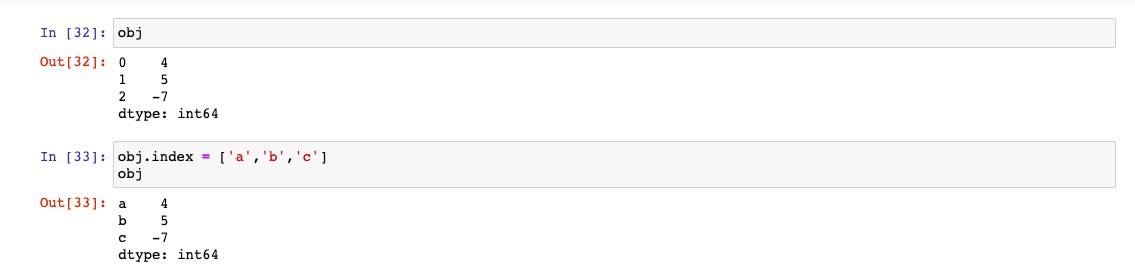
自定义索引
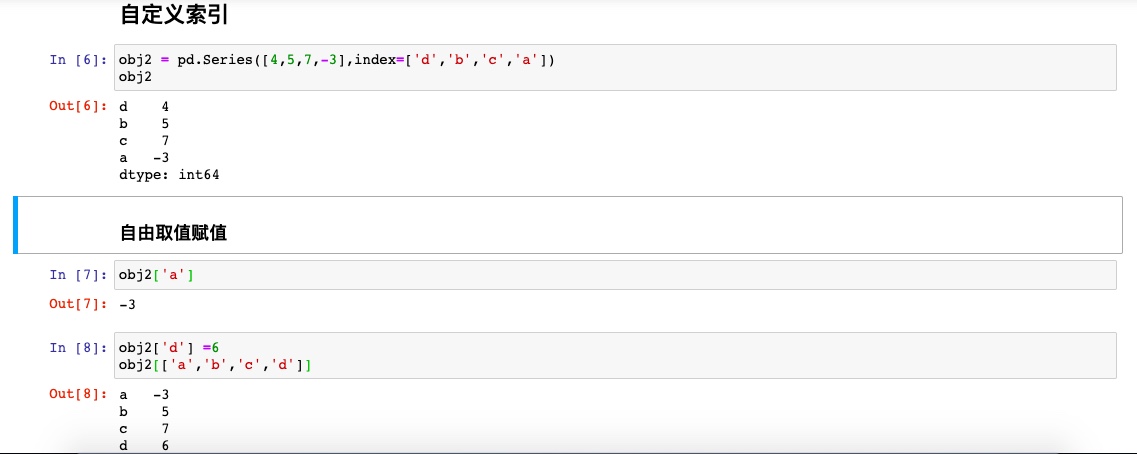
一些运算
类比定长的有序字典

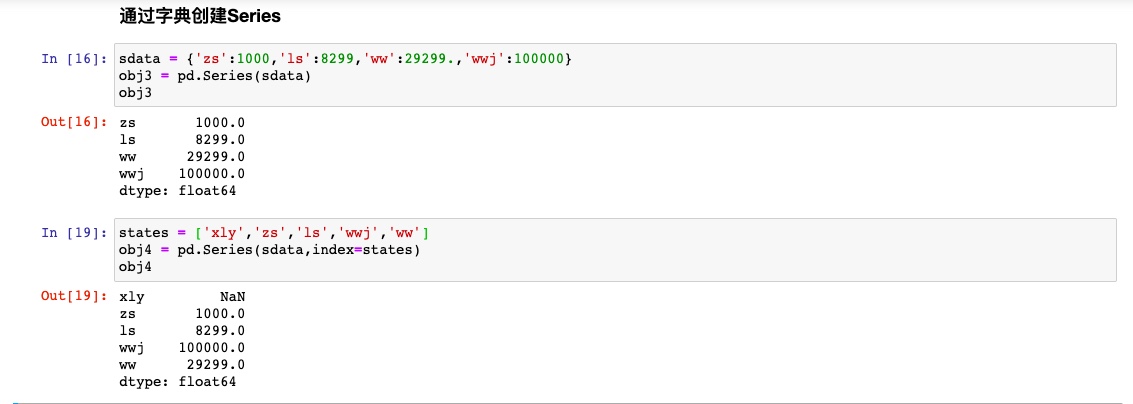
通过字典创建Series
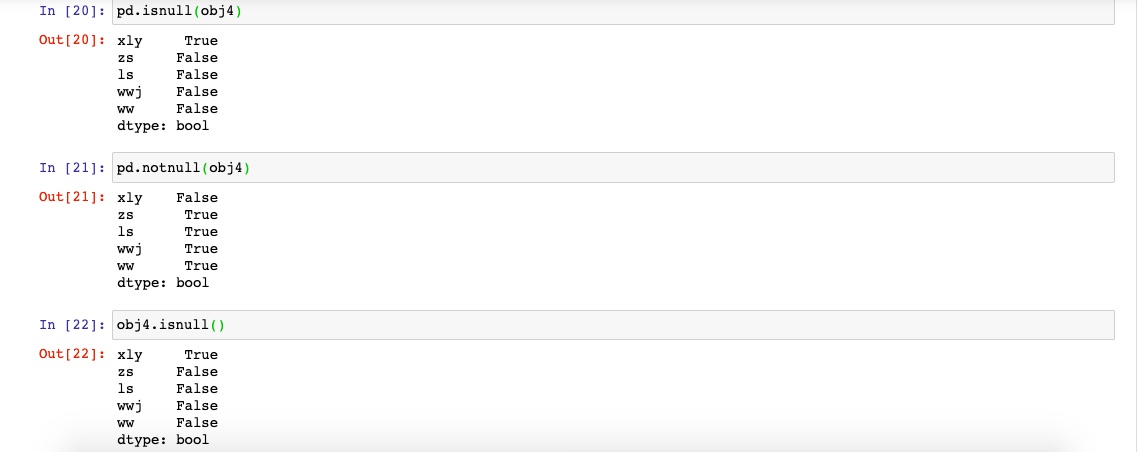
检测缺失值
重要功能
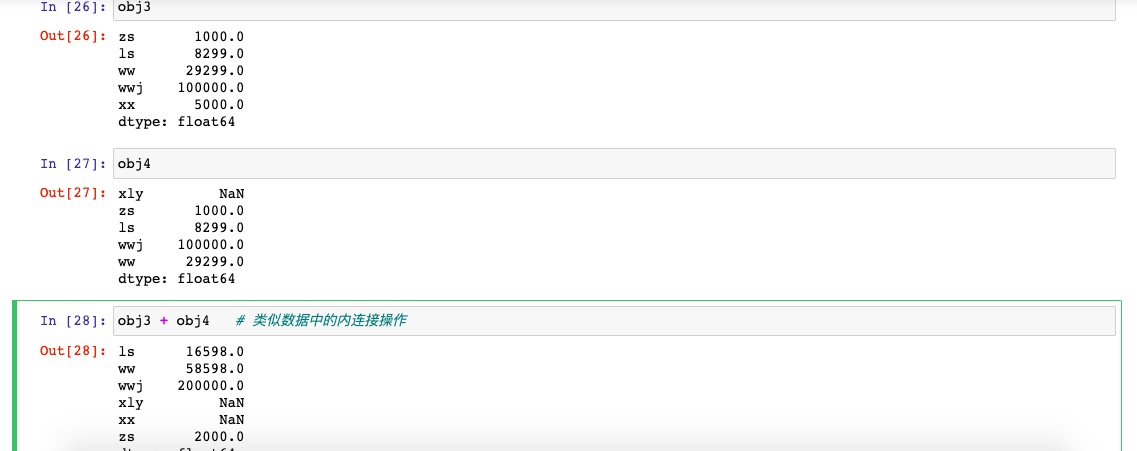
Series最重要的一个功能是会根据运算的索引标签自动对齐数据
Series对象本身和索引都有一个name属性,这个属性和pandas的其它关键功能非常密切

DataFrame
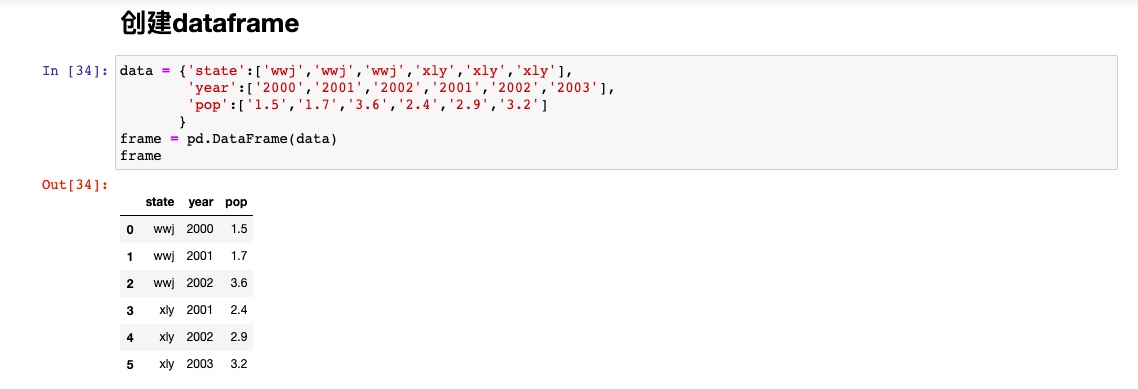
DataFrame是一个表格型的数据结构,含有一组有序的列,每列可以是不同的值类型。
DataFrame既有行索引也有列索引.其中的数据是以一个或多个二维快存放的
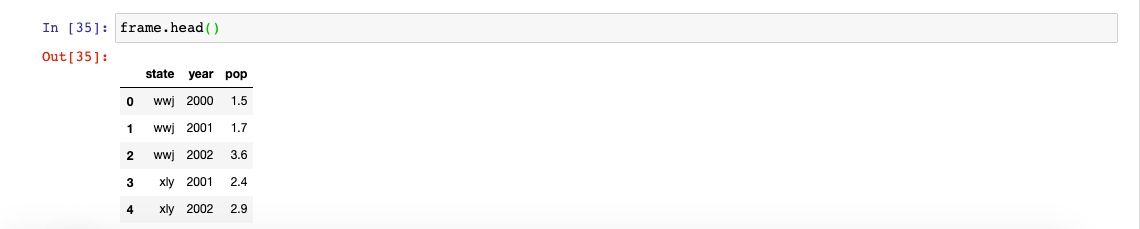
通过head方法取前5行数据
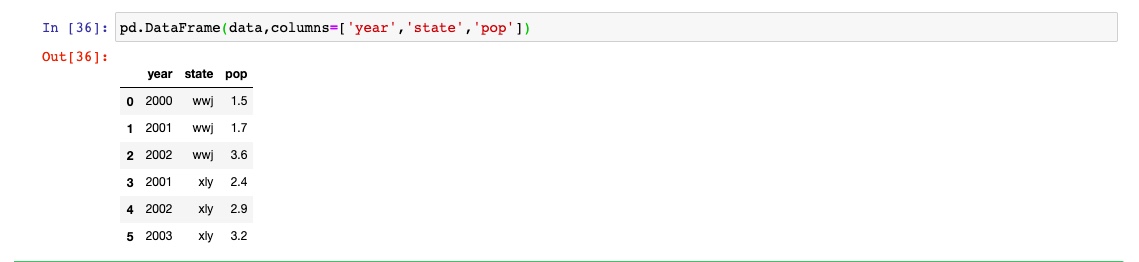
可以指定具体列进行排列
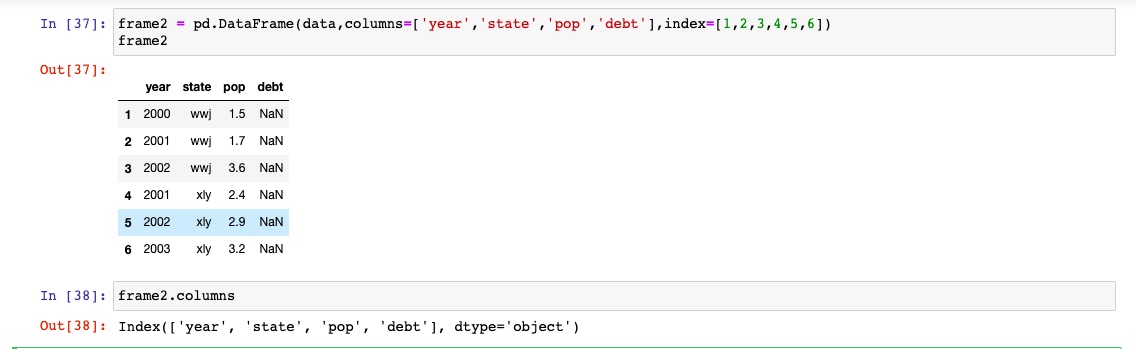
如果传入列数据找不到产生缺失值
通过字典表及或者属性方式可以获取一个series
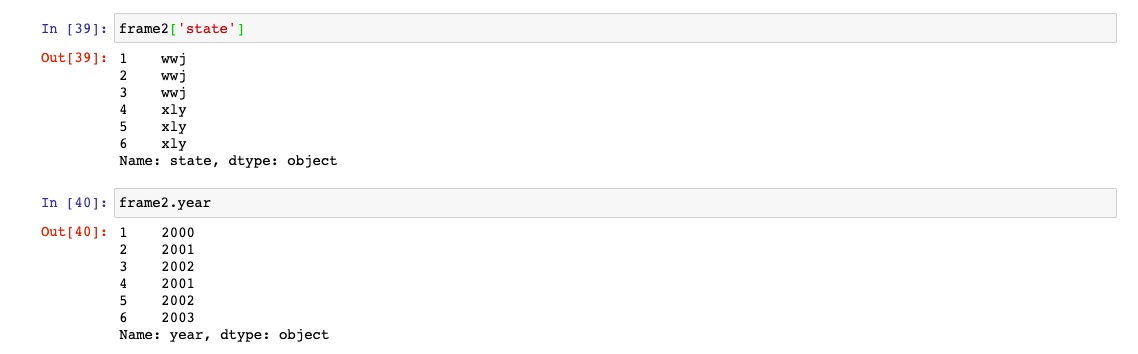
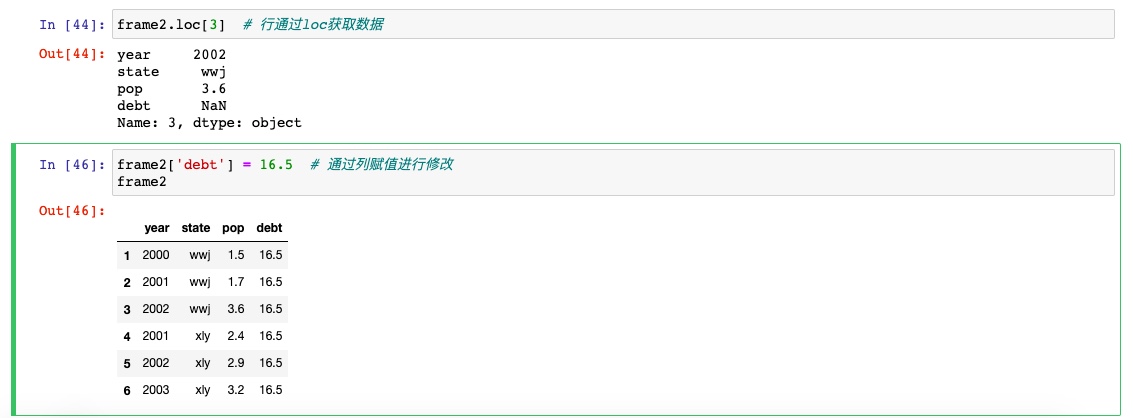
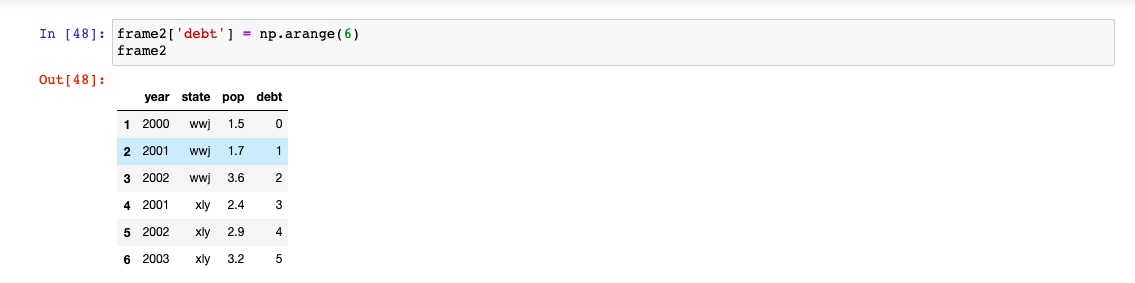
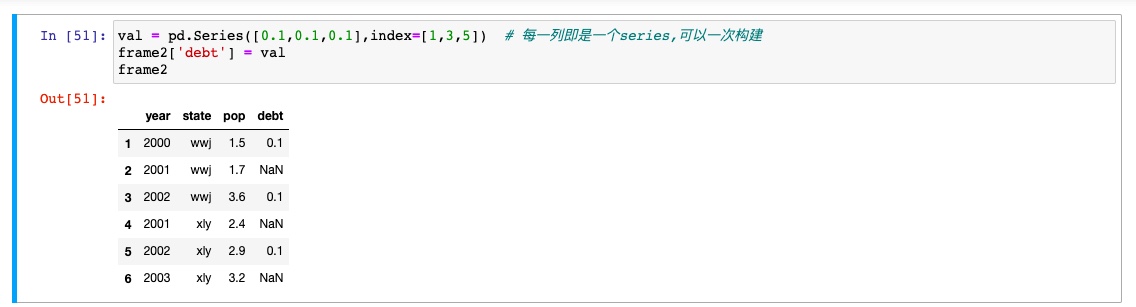
行值和列值得获取
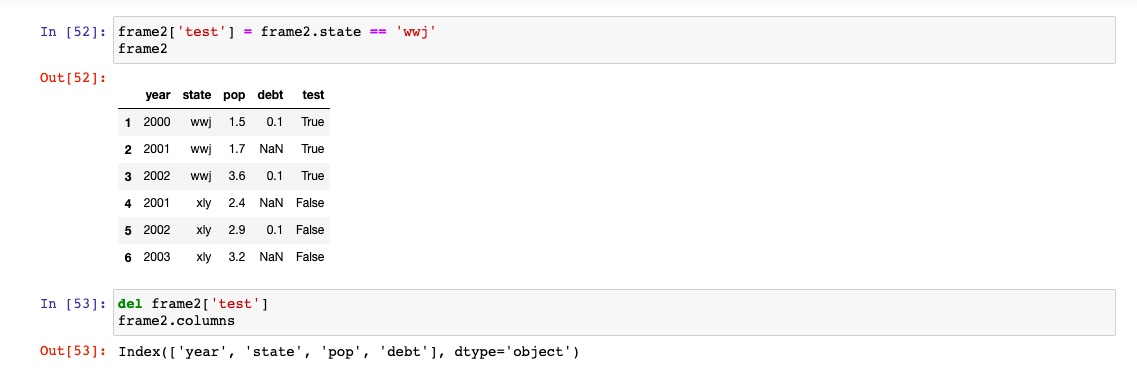
使用del删除列
处理另一种常见的数据(嵌套字典)
嵌套字典转换为dataframe,外层字典的键作为列,内层键作为行索引
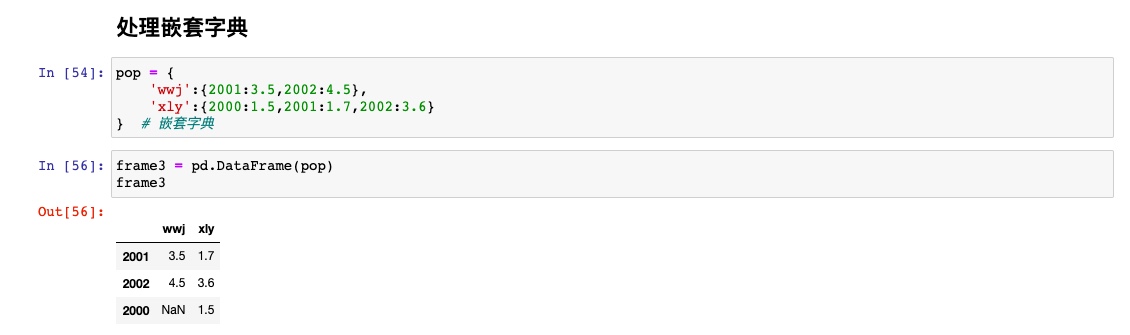
可以用T方法进行行和列的交换

索引对象
pandas的索引对象负责管理元数据,无论构建哪种类型,用到的任何数组和序列都会转换成一个Index
注意:与集合不同,pandas的索引是可以包含重复的标签
索引一些方法和属性
