只有清晰的明白流和表,你才有可能明白聚合以及开窗
知识要点
- 流与表的关系
- 记录流概念
- 更新记录和日志
- 2者之间的对比
- 工作原理
流与表的关系
在生活中,我们无时无刻都在产生一些事件,每个事件上面都可以看成在历史的记录中不断的添加一笔新的操作.而这些记录与其他的记录无关,都是独立的。
记录流的概念
流被定义为无限的事件序列
例如股票市场中,每只股票的报价都是一个离散时间,它们彼此之间没有任何关联。即使一家公司股票有多次报价。在某个时候我们称作为记录流,如图:
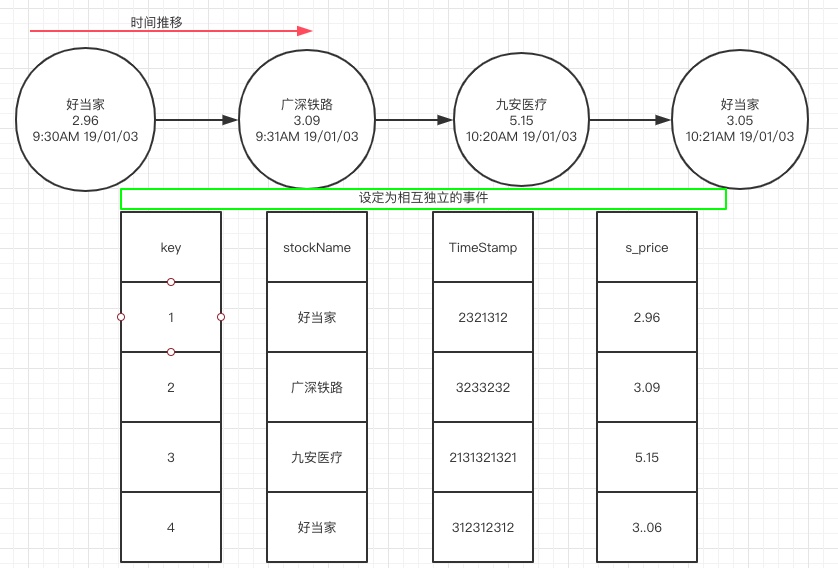
每个时间就是一个插入项,为表中每个插入项建立一个地增量为1的key
更定记录和变更日志
如果讲事件流看成是一个日志,更新流可以看成是一个不断在变更的日志。
如上图所示,如果以股票名字作为主键。那么动作发生将是更新操作。
注意:日志和变更日志都是讲记录追加到文件末尾,在日志中可以看到所有的记录.但是在变更日志中,对任何一个给定键只保留最新记录。
对于变更日志和更新流来说,我们用KTable进行抽象的表现与描述
2者之间的对比
通过代码我们来进行呈现说明
构建股票信息类StockMsg
1 | public class StockMsg { |
改进通用化序列器
1 | public class WrapperSerde<T> implements Serde<T>{ |
类序列器的构建
1 | public class StockSerde extends WrapperSerde<StockMsg>{ |
构建流式程序
1 | public class KTVSKS_Stream { |
模拟生产者
1 | public static void main(String[] args) { |
测试
- 启动zookeeper
- 启动kafka
- 创建主题–STOCKTOPIC 和 STOCKTOPICTABLE
- 启动流程序 (需要指定key值)
- 模拟数据发送
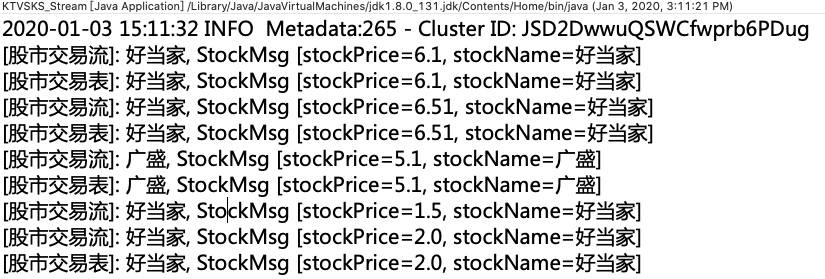
注意:表始终在更新以最新的标准被基准,当然前提是流有进行过选择对应的key值
工作原理
1.在创建KTable的时候,同时在后台创建了一个追踪流状态的状态存储,从而创建了一个更新流。创建后会有一个内容名称,但是 不能显式的进行交互式访问。但是KTable通过使用Materialized(计量)可以进行显式的查询
2.KTable何时进行更新,并发往下游处理器.
因素
- 较高的数据流入速率将增加发送更新记录的频率
- 不同键越多
- 通过配置cache.max.bytes.buffering以及commit.intrval.ms达到更新的设置
cache.max.bytes.buffering设置缓存缓冲大小
设置该缓存用于删除具有相同键重复的更新记录。使用持久化存储时就可以显著提升性能
commit.intrval.ms设置提交时间间隔
提交间隔参数用来指定保存数据的频率,它会强制刷新,将最新的记录更新,并发送到下游
注意:默认的提交时间是30秒以及默认10M缓存,当然在上线之前,肯定要平衡大小和时间以及处理的线程数。这个是需要进行考量的。