连接以为可以观测时间,有了时间,我们才会具有洞察力.
知识点
- 连接的目的,增加洞察力
- 时间戳的定义以及分类
连接的目的
在前期我们通过给定谓词(也就是加入筛选条件)将流分为了2类,比如钥匙类和小五金类
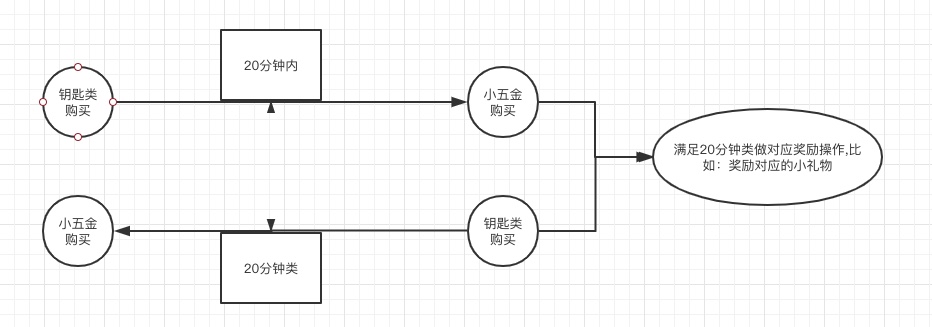
如何让这2个不同的流连接在一起,能够观察增加需求能力。
连接的要求
- 2个流以上
- 有一个相同的key,作为连接的条件
前期code如下
1 | public class JoinStream { |
如何建立连接
- 连接的记录,需要创建一个ValueJoiner<V1,V2,R>对象.V1和V2代表着接收的2个连接对象,他们应该有相同的key.类型可以不同。R代表着可以选择组合后返回的新的对象
新的合并对象设计
对象设计如下:
1 | public class CorrelatedPurchase { |
ValueJoiner设计代码如下:
1 | public class PurchaseJoiner implements ValueJoiner<PurchaseRecord, PurchaseRecord, CorrelatedPurchase> { |
实现连接
1 | public class JoinStream { |
代码测试
[joinedStream]: 王小十四, CorrelatedPurchase [firstDate=Mon Dec 30 11:18:12 CST 2019, seconDate=Mon Dec 30 11:18:21 CST 2019, purchaseListItem=[小小锅, 小小锅], totalAmount=40.0]
[joinedStream]: 王小十四, CorrelatedPurchase [firstDate=Mon Dec 30 11:18:45 CST 2019, seconDate=Mon Dec 30 11:18:21 CST 2019, purchaseListItem=[小小锅1, 小小锅], totalAmount=40.0]
[joinedStream]: 王小十四, CorrelatedPurchase [firstDate=Mon Dec 30 11:19:30 CST 2019, seconDate=Mon Dec 30 11:19:58 CST 2019, purchaseListItem=[榔头, 锤子], totalAmount=40.0]
[joinedStream]: 王小十四, CorrelatedPurchase [firstDate=Mon Dec 30 11:19:46 CST 2019, seconDate=Mon Dec 30 11:19:58 CST 2019, purchaseListItem=[打榔头, 锤子], totalAmount=40.0]
[joinedStream]: 王小十四, CorrelatedPurchase [firstDate=Mon Dec 30 11:21:12 CST 2019, seconDate=Mon Dec 30 11:20:57 CST 2019, purchaseListItem=[锤子1, 锤子], totalAmount=40.0]
[joinedStream]: 王小十四, CorrelatedPurchase [firstDate=Mon Dec 30 11:31:31 CST 2019, seconDate=Mon Dec 30 11:31:09 CST 2019, purchaseListItem=[锤子4, 锤子2], totalAmount=40.0]
[joinedStream]: 王小十四, CorrelatedPurchase [firstDate=Mon Dec 30 11:31:31 CST 2019, seconDate=Mon Dec 30 11:31:17 CST 2019, purchaseListItem=[锤子4, 锤子3], totalAmount=40.0]
只要符合交易时间,都会出发对应的链接操作.只要满足连接操作,可用foreachAction或者发送主题信息做对应的逻辑动作
连接的进阶
记录的先后顺序
从上面结果可以看到,数据的时间并没有关注先来后到,只要满足1分钟之内及产生逻辑
如何要指定顺序:
需要使用 JoinWindows.after 或者 JoinWindows.before
分别代表着 streamA.join(streamB) B的记录时间戳比A的记录时间滞后或者是提前.
连接的前提首要条件
在Stream中执行连接操作,必要要保证数据具有相同数量的分区,按键分区且键的类型相同
通过selectKey出发了重新分区的要求。这个是被自动处理的.这个动作我们归纳为协同分区
连接的动作
- join 等同于 innerjoin
- outerJoin 等同于左右连接都满足
- leftJoin 只需要左连接
kafkaStreams中时间戳
时间戳的作用有3点:
- 连接流
- 更新变更日志
- 决定方法合适被触发
时间戳被kafkaStreams分为了三类
事件发生时间
特指事件发生时候的时间,通常设置在内置对象中,当然也可以考虑创建生产者的时间为事件时间
摄取时间
特指数据首次进入数据处理管道时设置的时间戳。可以考虑日志追加时间LogAppendTime作为摄取时间
处理时间
特指数据或者记录首次开始流经处理管道时设置的时间戳。
处理不同的时间语义
- 时间戳提取器 TimeStampExtractor接口
- kafkaStreams自带一个处理时间语义WallclockTimestampExtractor本质是通过调用系统当前时间,以毫秒数返回当前时间
自定义时间戳
代码示例如下:
1 | public class TransactionTimestampExtractor implements TimestampExtractor{ |
配置方式
- 一种是在流程序中统一添加
props.put(StreamsConfig.DEFAULT_TIMESTAMP_EXTRACTOR_CLASS_CONFIG, TransactionTimestampExtractor.class);
- 一种是在Consumed中配置
Consumed.with(Serdes.1,Serdes.2).withTimestampExtractor(new TransactionTimestampExtractor());
梳理当前的DAG