kafkaStreams运行在kafka之上。没有kafka理论先行,很难始于足下。
kafka的上门之路
- kafka架构
- 生产者和消费者
- kafka的安装和运行
kafka架构
- kafkaStreams是运行在kafka之上的一个库
示例
比如现在某个公司有3个系统。销售系统,营销系统,审计系统。系统之间数据可以相互共享获取
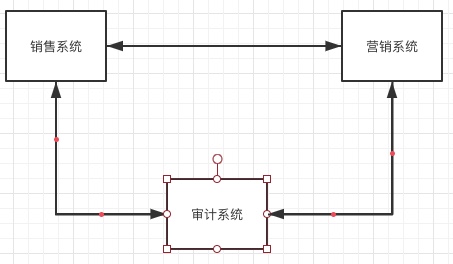
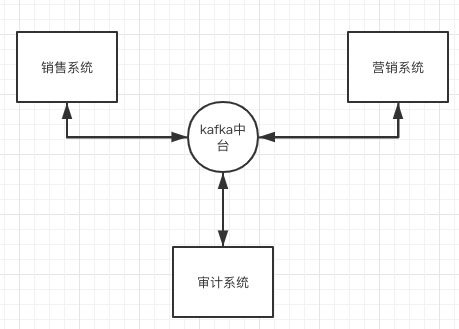
如果随着系统越来越多,数据相互之间都需要共享。这个时候可以使用kafka来做为数据中台。它满足几点要求
- 数据中心是无状态的
- 以一种方式接受交易数据并存储,消费程序可以根据自己的需要从数据中心提取信息。
- 数据中心只知道交易数据要保存多久。以及什么时候切分和删除这些数据
kafka介绍
一个具有容错能力,健壮的发布/订阅系统,一个节点称为一个代理。多个代理组成一个集群。
kafka将生产者写入的消息存储在kafka的主题中,消费者订阅kafka主题。与kafka通信查看主体是否有可用的信息*
kafka是一个消息代理
- kafka是一个中介,将进行交换或交易但是不一定相互了解的两部分汇聚一起。
- kafka将消息存储在主题中,从主题检索消息.本身不会和消费者和订阅者保持任何状态.仅作为一个消息中心
- kafka底层技术用的是日志,不断追加输入记录文件。
- 主题的消息负载,kafka使用分区。
kafka是一个日志
- 日志用于记录应用程序正在做什么,如果程序出现问题。首先检查的是应用程序日志。
- 在kafka设计理念中,日志是一种只能追加的,完全按照时间顺序排列的记录序列
- 日志是具有强大含义的简单数据抽象.如果记录时间有序。解决冲突或者确定哪个数据更新到不同的机器就更加的明确
- kafka的日志是按照主题名称分隔日志的,如果日志在一个集群中有多个副本。如果一台服务器宕机。从故障中回复是分布式提交日志具有的。
这也分布式应用程序和数据一致性的基本要求
kafka日志工作原理
- kafka将每个主题映射到指定日志路径的下一个子目录。子目录数和主题对应的分区数相同。
- 每个目录里面存放都是追加传入消息的日志文件
- 一旦日志文件达到某个规模,日志文件就会被切分。消息会追加到一个新的日志文件中.
比如: /logs/topicA_0 logs是消息存储的根目录,目录下代表着主题的分区,下划线后面紧跟分区编号
kafka和分区
- 分区能够保证同一个键的数据按序发送给同一个消费者
- kafka将每个传入的消息追加到日志末尾,消息都严格按照时间排列.不保证跨分区有序,但能保证每个分区消息有序
分区无键和有键的方式
键为空,生产者按照轮询的方式选择分区写入记录
键不为空,则按照 hascode.(key) % number of partitions
自定义分区
1 | public class PurchaseKeyPartitioner extends DefaultPartitioner { |
可以在生产者配置上设置properties.put("partitioner.class", PurchaseKeyPartitioner.class.getName());
分布式日志
kafka提供了数据冗余,数据被写入到一个节点的时候,数据会被复制到一台或者多台机器上
其次选择zookeeper作为代理控制器目的在于:
- 集群成员
- 主题配置
- 访问控制
日志管理
- 传统的日志删除通过设置log.roll.ms会对日志进行切分
- 通过设置log.retention.ms会设置日志的保留时间
- 日志压缩通过这只log.cleanup.policy = compact可以设置日志压缩
注意:如果消息是独立的.就可以用日志删除.如果是需要对消息又更新最新点上面的操作,就可以使用日志压缩
生产者和消费者
1 | Properties properties = new Properties(); |
生产者可指定分区和时间戳以及指定分区
指定分区和时间戳
- 构造器重载有4个方法,可以指定分区和时间戳
- 分区位置平均可以考虑 AtomicInteger count = new AtomicInteger(0);
- AtomicInteger类的理解与使用
消费者
首先生产者是无状态的,但是消费者需要周期性的提交从代理中消费过的消息的偏移量来管理一些状态。
消费者提交一个偏移量有以下含义
- 意味着消费者完全处理了消息
- 也表示发生故障或者重启时该消费者消费的起始位置
如果创建了消费者发生了某些故障,并且最后的提交的偏移量不可用。消费者从何处开始消费取决于具体的配置
- earliest从最早可用的偏移量检索消息
- latest本质从消费者加入集群的时间点开始消费消息
- none代理将会向消费者抛出异常
同样消费者可以自动提交偏移量,以及手动提交偏移量
消费者代码示例 (引用书中代码)
1 | public class ThreadedConsumerExample { |
Java ExecutorService四种线程池的例子与说明
kafka的安装和运行
- kafka选择版本 2.12-1.1.0
- 默认情况下kafka使用9092端口,zookeeper使用2181端口
- kafka的配置在config的server.properties中-日志配置在log.dirs
- zookeeper在zookeeper.properties中-日志在dataDir中


操作步骤
1.先启动zookeeper
kafka_2.12-1.1.0 % bin/zookeeper-server-start.sh config/zookeeper.properties

2.启动kafka
bin/kafka-server-start.sh config/server.properties

3.创建一个主题供生产和消费进行操作
bin/kafka-topics.sh --create --topic first-topic --replication-factor 1 --partitions 1 --zookeeper localhost:2181
replication-factor 副本设置为1表示不复制。实际中副本因子为奇数以上以便发生故障时保证数据可用性
partitions 指定主题将用到的分区数。如果需要更高的负载,需要更多的分区。

4.通过生产者控制台发送消息
bin/kafka-console-producer.sh --topic first-topic --broker-list localhost:9092

5.通过消费者控制台接收消息
bin/kafka-console-consumer.sh --topic first-topic --bootstrap-server localhost:9092 --from-beginning
from-beginning 消费者为从头接受消息,但没有提交偏移量
