mybatis是一个优秀的开源框架,半自动ORM映射,能够适配各种业务需求
mybatis的路线图(上)
- mybatis简介
- mybatis框架执行原理
- mybatis初次的入门案例
- mybatis配置文件详解
- mybatis 方法多参数的处理
- mybatis返回主键值
- sql代码段
- 自定义结果类型ResultMap
mybatis简介
mybatis本身是一个轻量级的持久化层框架(1.何为持久化。2.何为序列化操作),本身也是基于JDBC的封装(JDBC的链接步骤).开发者本身更多的关注SQL语句的执行效率,除此之外mybatis也是一个半自动的ORM映射框架(支持一对一,一对多的实现,多对多采用两个一对多进行实现)
注意:实际的开发过程中,因为大量的关系相互映射的存在,在查询数据这一块不便于后期项目本身的项目维护扩展。所以更多的方向是思考数据库中的设计和利用本身mybatis提供的数据自定义封装和其它的类似缓存机制的特点,解决开发中的数据设计结构
mybatis的优势
比起jdbc的操作,减少了一些重复的代码量工作,也方便能够集成到后期的管理框架中
mybatis提供在XML中编写sql语句,不直接入侵在代码中(方便分类修改)
分别提供的xml标签和mapper标签(xml标签可实现动态SQL语句,也就是嵌入条件判断和循环,比较类似存储函数),mapper标签支持对象正确的解析至数据库中
mybatis框架执行原理
sqlConfigXMl配置文件(一个全局的配置文件)(可配置映射文件和连接数据源和事务等)
通过配置文件构建出可构建操作数据会话的会话工厂,也就是我们常说的sqlSessionFactory(涉及工厂模式代码设计)
通过sqlSessionFactory生产出相互独立的sqlsession,为什么是独立的会话,既然是独立的会话,那也有全局的会话(简单提及缓存)进行数据库层面上面的操作
sqlsession之所以能够操作,依赖一个叫Executor的执行器,通过该执行器进行数据库的CRUD操作
Executor的执行器需要操作CRUD的动作由谁而来,就是由mapperstatement对象读取mapper映射文件
我们可以看到在配置xml文件的时候,可以支持多种对象级数据参数
mybatis初次的入门案例
- 配置一个log4j.properties(可选)方便我们监听到mybatis进行的动作
1 | \# set level |
- 构建一个普通的web项目,jar包结构如下:
- src目录下构建mybatis的全局配置文件mybatisCfg.xml,配置文件如下:
1 | <?xml version="1.0" encoding="UTF-8"?> |
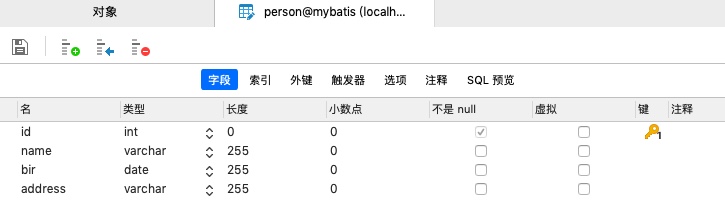
- 构建模型类 com.wwj.model 和 数据库表
1 | import java.io.Serializable; |
- 创建数据层的操作也就是mapper的操作接口
1 | /** |
- 构建对应的mapper映射文件
1 | <?xml version="1.0" encoding="UTF-8"?> |
- 编码测试
1 | /** |
注意:mysql中设置为date支持的格式为yyyy-mm-dd,java中的date是格林威治时间
结果图示

同理依次测试更新和删除,以及查询
更新的调用操作
1 | Person per = new Person(); |

查询的调用操作
List<Person> pers = session.selectList("getPersonInfos");
删除的调用操作
int de = session.delete("deletePersonById", 1);
mybatis配置文件详解
全局配置文件详解
- environments环境配置,可以配置多种环境 default指定使用某种环境.
- transactionManager事务管理器有两种取值JDBC,managed.我们选择jdbc即可
- dataSource配置数据源,采用默认的连接池选择项POOLED
- mappers里面填入需要进行数据操作xml标签用于执行的动作
- 映射的数据操作文件需要和接口保持同个路径(可以把mapper当成接口的实现类)
映射文件详解
- namespace表明需要对应动作的空间即是接口所在的全路径名称
- id与接口中的方法保持一致
- parameterType填写自定义对象的全路径名称
- 接收参数采用 #{objAttrName}
mybatis方法多参数接收(代码示例)
索引接收(了解即可)
1 | List<Person> getPersonInfosByNameAndID(String name ,int id); |
map接收(重点)
1 | /** |
注解@Param接收(重点)
1 | /** |
mybatis立即返回主键值
应用场景:当我们需要在当前事务插入数据后立即获取数据的主键id,做下一步额外操作,并且不因为并发高的情况下取错值而考虑
修改代码如下
1 | <insert id="savePerson" parameterType="com.wwj.model.Person"> |
- keyProperty=”返回主键的id的属性名”
- resultType=”主键类型”
- order=””什么时候执行,在SQL执行前还是执行后执行,两个取值:BEFORE和AFTER
- select last_insert_id()取到最后生成的主键,只在当前事务中取
sql代码段
如果场景中有大量的重复的公共sql语句,那么可以考虑使用<sql>声明公共的部分
示例如下:
1 | /** |
自定义结果类型ResultMap(开发中长期使用)
应用场景:假设我们的实际开发过程中,数据表组合字段多,又不想关心配置映射关系,只想关心sql语句,以及结果,并且也关心sql语句的效率
- 假设2张表 person和card 1:m关系
- 连接查询需要person中的人名和card表中的卡号名字
操作步骤如下:
- 在任意自定对象上添加属性
1 | //----- 实体类 |
注意1:po代表和数据库一一对照的数据模型.vo代表业务逻辑和表现层之间需要的数据
注意2:如果需要暴露一部分数据出去的,可能还是会单独做接口和设计VO