Oracle数据库也是一个数据库的中间力量
oracle数据库操作
- Oracle 常用数据类型
- Oracle 中常用的操作符
- Oracle 常用函数
- Oracle 中的序列 和 Oracle 中的查询
- Oracle 中的视图
- Oracle 中的触发器
- Oracle 中的存储过程
oracle常用的数据类型
分为字符型,数字类型,日期,blob
字符类型
VARCHAR2 (n):可变长度的字符,最大长度4000bytes,即1<=n<=4000,VARCHAR2(10),表示占10个字节的字符串,当长度小于10字节时,不会自动补空格,占实际大小,大于则报错
数字类型
NUMBER(P,S):P为整数位+S小数位数.例如NUMBER(5,3),表示整数位数为2,小数位数为3的数字,如25.112
日期类型
data缺省格式为DD-MON-YY,timestamp同样,精确到纳秒
LOB类型
BLOB:二进制数据,最大长度4G. CLOB:字符数据,最大长度4G,一般音视频类就BLOB,文献就CLOB
oracle常用的操作符
比较操作符
- =、!=、<、>、<=、>=、BETWEEN AND (检查是否在两个值之间)
- [NOT] IN(与列表中的值匹配)
- [NOT] LIKE(匹配字符模式, * _ 通配符)
- [NOT] IS NULL(检查是否为空)
逻辑操作符
- and or not
- 如果and和or混用,and的优先级高于or,所以尽量的使用括号来表明优先级
集合操作符
- UNION(联合) 返回两个查询选定不重复的行。( 删除重复的行 )
- UNION ALL(联合所有) 合并两个查询选定的所有行,包括重复的行。
- INTERSECT(交集) 只返回两个查询都有的行。
- MINUS(减集) 在第一个查询结果中排除第二个查询结果中出现的行。 (第一 – 第二)
注意:使用集合操作符的时候列的数量和数据类型,都要保持一致
连接操作符
- 使用||进行连接,返回字符串
SELECT ('wwj' || 'hello') as str1 FROM dual
oracle常用的函数
字符串函数 (subsrt 和 replace 和 decode)
SELECT SUBSTR(ch, pos, length) as str1 FROM dualpos代表等于0或1时,都是从第一位开始截取
length代表要截取的字符串的长度
如果pos填写为负数,为倒着截取
SELECT REPLACE('wwj','j','q') as str1 FROM dual将字符串中包含j的替换成q
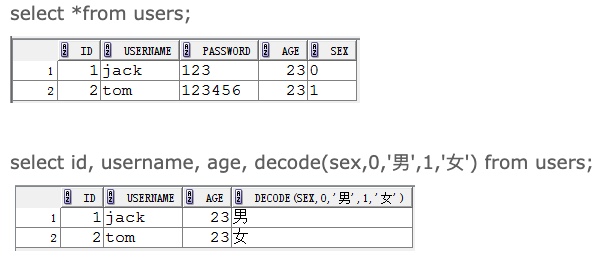
decode(条件,值1,返回值1,值2,返回值2) 等同于 if elseif
数学函数 (round 和 trunc )
SELECT ROUND(n, int) as num1 FROM dualint位置代表保留几位小数,并且四舍五入
SELECT TRUNC(n1, n2) as num1 FROM dualn2代表保留几位小数,并不四舍五入
转换函数(tochar 和 todate)
SELECT to_char(SYSDATE,'Day, HH12:MI:SS') FROM dual;
SELECT TO_CHAR(99,'$99.9999') FROM dual;SELECT to_date('2089-5-7 17:09:37','yyyy-mm-dd HH24:MI:SS') from dual
其它函数
nal(expr1,expr2)代表 oracle第一个参数为空那么显示第二个参数的值,如果第一个参数的值不为空,则显示第一个参数本来的值。
比如:
select ename,NVL(comm, -1) from emp;如何comm没值,则取-1
Oracle 中的序列 和 Oracle 中的查询
- mysql数据中提供了数据库自增的选项,但是oracle中没有提供,只有利用序列实现主键自增的功能
- sequence 就是序号,也可以说是序列
序列创建的语法
创建
1 | CREATE SEQUENCE seq1 |
查看与操作序列信息
select * from user_sequences;Select * from all_sequences;使用序列名.CurrVal:返回 sequence的当前值
使用序列名.NextVal:增加sequence的值,然后返回 增加后sequence值
select seq1.currval from dual
- 重新初始化seq的序号(可以使用修改)
alter sequence seq1 increment by 1
- 删除seq
drop sequence seq1
数据模拟
emp 员工表(empno 员工号/ename 员工姓名/job 工作/mgr 上级编号/hiredate 受雇日期/sal 薪金/comm 佣金/deptno 部门编号)
dept 部门表(deptno 部门编号/dname 部门名称/loc 地点)
创建部门表
1 | create table dept( |
创建员工表
1 | create table emp( |
模拟数据
1 | insert into dept values(seq1.nextval, '技术部' ,'南泥湾'); |
1 | INSERT INTO "EMP"("EMPNO", "ENAME", "JOB", "MGR", "HIREDATE", "SAL", "COMM", "DEPTNO") VALUES ('1', '关羽羽', 'CLERK', '刘备备', '20011109', '2000', '1000', '3'); |
rownum分页
SELECT ROWNUM , dept.* FROM dept
1 | SELECT * FROM |
计算起始位置和结束位置
startNum = (pageNo - 1) * pageSizeendNum = (pageNo * pageSize) + 1
查询
分组查询使用group by 和 having 进行过滤条件筛选
子查询也就是条件中加入查询语句
连接查询,内连接(利用where或者inner join),左和右连接(left join 和 right join),自连接(树菜单结构)
数据操作
1.列出至少有一个员工的所有部门。
select deptno,dname,loc from dept where deptno in (select deptno from emp);
2.列出薪金比“SMITH”多的所有员工。(大于最大薪水SMITH员工)
select empno,ename,sal from emp where emp.sal>(select sal from emp emp1 where emp1.ename = 'SMITH')
3.列出所有员工的姓名及其直接上级的姓名。
select a.ename,b.ename from emp a,emp b where a.mgr=b.ename;
4.列出受雇日期早于其直接上级的所有员工。
select a.empno, a.ename from emp a, emp b where a.mgr=b.ename and a.hiredate<b.hiredate;
5.列出部门名称和这些部门的员工信息,包括那些没有员工的部门。
select dept.dname,emp.* from dept left join emp on dept.deptno = emp.deptno;
6.列出所有job为“CLERK”(办事员)的姓名及其部门名称。
select emp.ename,emp.job,dept.dname from emp,dept where emp.job = 'CLERK' and emp.deptno = dept.deptno;
7.列出最低薪金大于1500的各种工作。
select job from emp group by job having min(sal)>1500;
8.列出在部门“SALES”(销售部)工作的员工的姓名,假定不知道销售部的部门编号。
select emp.ename from emp where emp.deptno = (select deptno from dept where dept.dname = 'SALES');
9.列出薪金高于公司平均薪金的所有员工。
select * from emp where emp.sal > (select avg(sal) from emp)
10.列出与“SCOTT”从事相同工作的所有员工。
select * from emp where emp.job = (select job from emp e where e.ename = 'SCOTT');
11.列出薪金等于部门3中员工的薪金的所有员工的姓名和薪金。
select ename,sal from emp where sal in (select sal from emp where deptno=3);
12.列出薪金高于在部门3工作的所有员工的薪金的员工姓名和薪金。
select ename,sal from emp where sal > (select max(sal) from emp where deptno=3);
13.列出在每个部门工作的员工数量、平均工资。
select deptno,count(empno),avg(sal) from emp group by deptno
14.列出所有员工的姓名、部门名称和工资。
select emp.ename as 姓名, dept.dname as 部门, emp.sal+emp.comm as 工资 from emp,dept where dept.deptno = emp.deptno;
15.列出从事同一种工作但属于不同部门的员工的一种组合。
select a.ename, b.ename, a.job, b.job, a.deptno, b.deptno from emp a,emp b where a.job=b.job and a.deptno$amp;
16.列出所有部门的详细信息和部门人数。
select dept.*,(select count(*) from emp where dept.deptno = emp.deptno) as pop from dept;
17.列出各种工作的最低工资。
select job,min((nvl(comm,0)+sal)) from emp group by job
18.列出各个部门的MANAGER(经理)的最低薪金(job为MANAGER)。
select emp.deptno, min(sal) from emp,dept where job = 'MANAGER' group by emp.deptno
19.列出所有员工的年工资,按年薪从低到高排序。
select ename,(nvl(comm,0)+sal)*12 年薪 from emp
oracle视图
当某个业务需要多个数据融合在一起展现的时候,可以利用视图
- 视图只查不改
- 其实就是一张虚拟表
语法(切换到sys grant CREATE any view to WANGWEIJIE)
1 | create or replace view v1 (maxsal,minsal,avgsal) |
oracle触发器
订单表和仓库表
1 | create table sorder( |
1 | create table sproduct( |
场景一:新增一个订单的时候,库存表数量减少 :new代表新行 和 :old代表删除和更新
1 | CREATE OR REPLACE TRIGGER abc1 |
场景二: 删除一个订单
场景三: 修改一个订单
Oracle 中的存储过程
无参数存储过程
1 | create or replace procedure p1 |
有参数的存储
1 | create or replace procedure p2(newname in varchar2) |
输出参数
1 | create or replace procedure p3(newname out varchar2) |